This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Python is a valuable tool for orchestrating any data flow activity, while Docker is useful for managing the data pipeline applications environment using containers. Let’s set up our data pipeline with Python and Docker. Step 2: Set up the Pipeline We will set up the Python pipeline.py file for the ETL process.
It helps you track, manage, and deploy models. It manages the entire machine learning lifecycle. MLflow also manages models after deployment. Managing ML projects without MLFlow is challenging. Reproducibility : MLFlow standardizes how experiments are managed. It saves exact settings used for each test.
Whether its integrating multiple data sources, managing data transfers, or simply ensuring timely reporting, each component presents its own challenges. BigQuery, Snowflake, S3 + Athena) Design schemas that optimize for reporting use cases Plan for data lifecycle management, including archiving and purging 5.
This API-first approach offers several advantages: you get access to cutting-edge capabilities without managing infrastructure, you can experiment with different models quickly, and you can focus on application logic rather than model implementation. Design user interfaces that set appropriate expectations about AI-generated content.
Functions and data: Functions, scope, recursion, lambda functions, and common data structures like lists, dictionaries, tuples, and sets. File and module operations: Reading/writing files, using external modules, command-line arguments, and setting up virtual environments. weather app).
Validation: Ensure data meets business rules and constraints Reporting: Track what changes were made during processing Setting Up the Development Environment Please make sure you’re using a recent version of Python. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: No, thanks!
No Cost BigQuery Sandbox and Colab Notebooks Getting started with enterprise data warehouses often involves friction, like setting up a billing account. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Latest Posts 8 Ways to Scale your Data Science Workloads Vibe Coding Something Useful with Repl.it
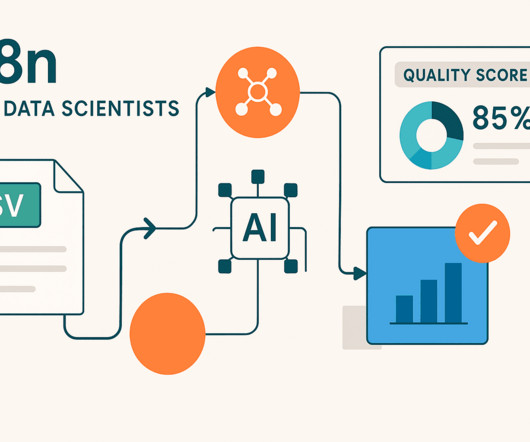
Step 4: Execute and View Results Click "Execute Workflow" in the top toolbar Watch the nodes process - each will show a green checkmark when complete Click on the HTML node and select the "HTML" tab to view your report Copy the report or take screenshots to share with your team The entire process takes under 30 seconds once your workflow is set up.
Every time you iterate through a Python loop, the interpreter has to do a lot of work like checking the types, managing objects, and handling loop mechanics. Similarly, when working with very small datasets, the overhead of setting up vectorized operations might outweigh the benefits. Its also much faster.
By Matthew Mayo , KDnuggets Managing Editor on July 17, 2025 in Python Image by Editor | ChatGPT Introduction Pythons standard library is extensive, offering a wide range of modules to perform common tasks efficiently. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: No, thanks!
Databricks provides efficient cost management controls to support incremental maturity among FinOps teams, aligning with industry standard FinOps core beliefs. These organizations manage thousands of resources in various cloud and platform environments. Think of this as the “Crawl, Walk, Run” journey to go from chaos to control.
Rather than managing the overwhelming complexity of agent development, teams can focus on what matters most: defining their agent's purpose and providing strategic guidance on quality through natural language feedback. We auto-optimize over the knobs, gain confidence that you are on the most optimized settings.
In this tutorial, we will: Set up Ollama and Open Web UI to run the DeepSeek-R1-0528 model locally. Abid holds a Masters degree in technology management and a bachelors degree in telecommunication engineering. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: No, thanks!
These protocols played a foundational role in advancing multi-agent research and applications, setting the stage for today’s more sophisticated and scalable agentic AI communication standards. It acts as the “project manager” of agentic systems, ensuring agents work together efficiently and securely.
A more advanced cost-tracking implementation will also allow users to set a spending budget and limit , while also connecting the LiteLLM cost usage information to an analytics dashboard to more easily aggregate information. Cornellius Yudha Wijaya is a data science assistant manager and data writer. I hope this has helped!
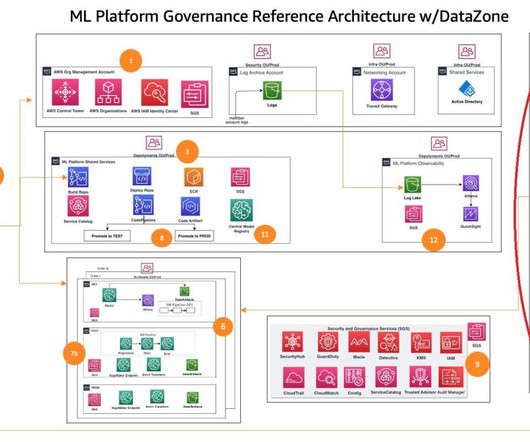
This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product. This post is part of an ongoing series about governing the machine learning (ML) lifecycle at scale.
There are many ways to set up a machine learning pipeline system to help a business, and one option is to host it with a cloud provider. The cloud provider selection is up to the business, but in this article, we will explore how to set up a machine learning pipeline on the Google Cloud Platform (GCP). Lets get started.
Unlike single-vector embeddings, multi-vector models represent each data point with a set of embeddings, and leverage more sophisticated similarity functions that can capture richer relationships between datapoints. Imagine you have a large dataset of "multi-vector sets" (i.e.,
They require the deliberate design and orchestration of context: the full set of information, memory, and external tools that shape how an AI model reasons and responds. Context engineering is the systematic design, construction, and management of all information—both static and dynamic—that surrounds an AI model during inference.
Set Up Your Data To set up the Excel workbook we will be using, follow these steps: Open a new Excel workbook Import your data into Excel Go to the Data tab >> select Get Data >> select your file type Perform any dataset cleaning or maintenance that may be required Convert to Excel Table Next, lets convert our data to an Excel table.
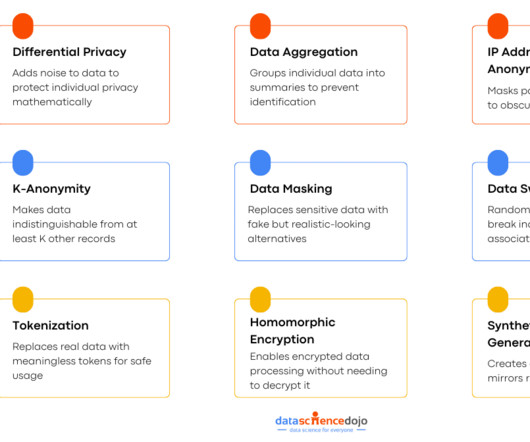
It is a powerful technique that allows AI to learn and improve without compromising user privacy. It means stripping away the personal identifiers that could tie data back to a specific person, enabling you to use the data for analysis or research while ensuring privacy. But how does it actually work?
In this tutorial, we will learn how to set up Modal, create a vLLM server, and deploy it securely to the cloud. Setting Up Modal Modal is a serverless platform that lets you run any code remotely. This tool lets you build images, deploy applications, and manage cloud resources directly from your terminal.
Remote data science jobs may appear similar to in-office roles on the surface, but the way they’re structured, managed, and executed varies significantly. Here’s what sets remote roles apart, according to studies and insights from top research institutions.
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on July 22, 2025 in Python Image by Author | Ideogram # Introduction Most applications heavily rely on JSON for data exchange, configuration management, and API communication.
In her 2022 tutorial, she guides you through setting up a countdown timer, Play/Pause/Reset controls, and visual feedback. You’ll manage enemy spawning, movement, collision detection, shooting logic, scoring, and even object‑oriented design. It is perfect for understanding event-driven programming and tkinter.
It offers a free tier with generous quotas and saves hours designers or managers would otherwise spend manually drawing visuals. Additional tools like global search across all messages, conversation archiving, send-later scheduling, and “stealth mode” (reading without notifying the sender) help you manage high message volumes efficiently.
With this launch, we’re handling the hard parts of MCP for you: our managed servers support on-behalf-of-user auth out of the box, respecting the governance you’ve already established in Unity Catalog. Built with enterprise-grade security in mind, our managed MCP servers automatically respect a user’s permissions.
Get a Demo Login Contact Us Try Databricks Blog / Product / Article What’s New: Lakeflow Jobs Provides More Efficient Data Orchestration Lakeflow Jobs now comes with a new set of capabilities and design updates built to uplevel workflow orchestration and improve pipeline efficiency. Salesforce, Workday, etc.) or directly from notebooks.
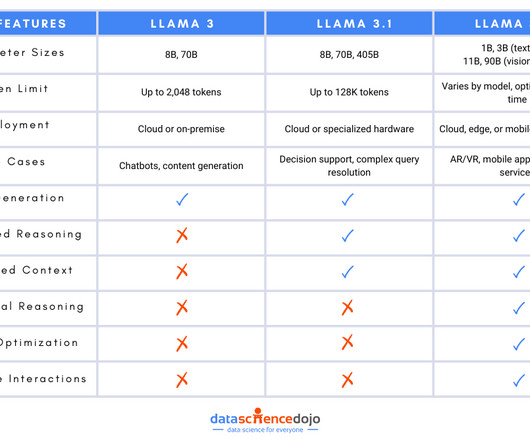
This release aimed to support real-time applications and ensure user privacy, making AI more accessible and practical for everyday use. Llama 3: Setting the Standard Llama 3 features a transformer-based architecture with parameter sizes of 8 billion and 70 billion, utilizing a standard self-attention mechanism. and Llama 3.2
Install them with: pip install pypdf langchain If you want to manage dependencies neatly, create a requirements.txt file with: pypdf langchain requests And run: pip install -r requirements.txt Step 1: Set Up the PDF Parser(parser.py) The core class CustomPDFParser uses PyPDF to extract text and metadata from each PDF page.
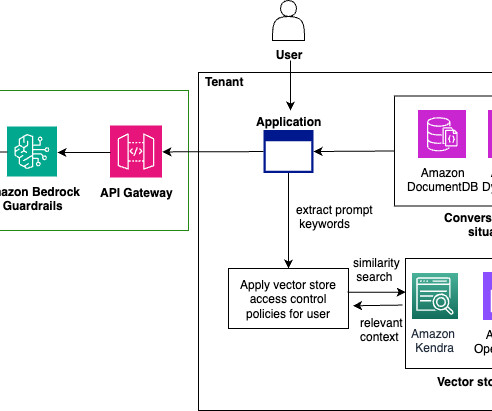
Architecting a multi-tenant generative AI environment on AWS A multi-tenant, generative AI solution for your enterprise needs to address the unique requirements of generative AI workloads and responsible AI governance while maintaining adherence to corporate policies, tenant and data isolation, access management, and cost control.
Concerns about legal implications, accuracy of AI-generated outputs, data privacy, and broader societal impacts have underscored the importance of responsible AI development. Denied topics are a set of topics that are undesirable in the context of your application. What constitutes responsible AI is continually evolving.
Cyber threats like identity theft, scams, and data breaches are on the rise, making privacy protection essential. What is privacy protection? Privacy protection refers to the steps you take to keep your personal information safe from cybercriminals, identity thieves, and data brokers. Why is privacy protection important?
Each component could be broken down into a smaller set of individual parts. The complete set of all parts is called a Bill of Materials (BOM). A graph consists of a set of nodes connected by edges. This produces the set of all reachable airports, along with the required number and set of flights.
torchft uses a global Lighthouse server and per replica group Managers to do the real time coordination of workers. Since we wanted to maximize the total number of failures and recoveries, we used Gloo since it can reinitialize in <1s for our use case, and we were able to set the timeout on all operations at 5s.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 13, 2025 in Artificial Intelligence Image by Author | Canva "AI agents will become an integral part of our daily lives, helping us with everything from scheduling appointments to managing our finances. Setting up the Agent First, let’s install all the libraries.
The assertion error helps users provide flexibility in development, as we can set up a failure-catching system that allows for easier debugging. Cornellius Yudha Wijaya is a data science assistant manager and data writer. By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: No, thanks!
As organizations generate more data, the need for clear guidelines on managing that data becomes essential. A data governance policy is a formal document that provides a structured framework for managing data and information assets within an organization.
It repeats this process until the captions stop improving, or it hits a set limit. Finally, we fine-tuned the model using a curated set of images for high-priority use cases, like frequently reported damage scenarios, to further improve accuracy and reliability. Shruti Tiwari is an AI product manager at Dell Technologies.
Home automation is basically the connection of different devices and technologies for automated and convenient work in managing the home environment. Current status: Management and automation Most smart homes today are scenario-based, which set predefined rules as actions. Water Management: Leakage and Overuse Detection Sensors.
To install Node.js, download it from nodejs.org To install pnpm, run the following command: npm install -g pnpm Step 3: Set Up Environment Variables cp.env.example.env Edit the.env file to include your OpenAI / Anthropic /OpenRouter API key and, optionally, your GitHub personal access token. and pnpm installed globally. start-database.sh
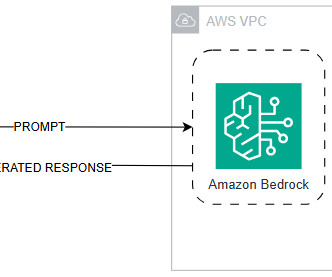
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Since Amazon Bedrock is serverless, you don’t have to manage any infrastructure, and you can securely integrate and deploy generative AI capabilities into your applications using the AWS services you are already familiar with.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content