


Frugality meets Accuracy: Cost-efficient training of GPT NeoX and Pythia models with AWS Trainium
AWS Machine Learning Blog
DECEMBER 12, 2023
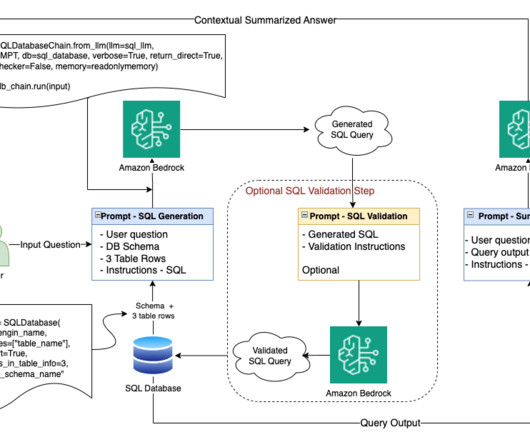
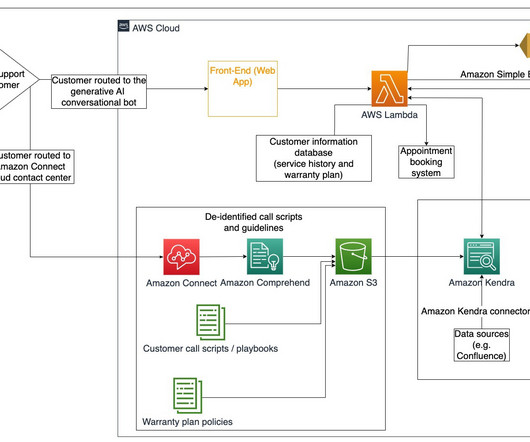
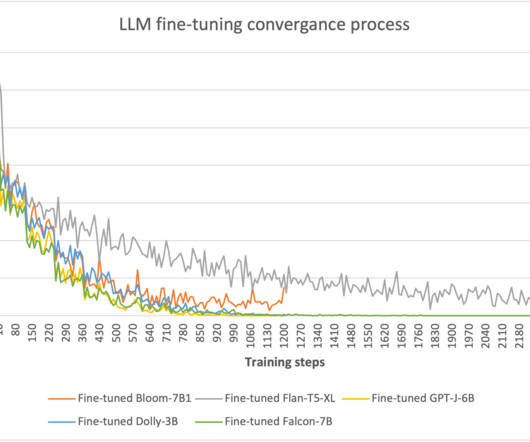
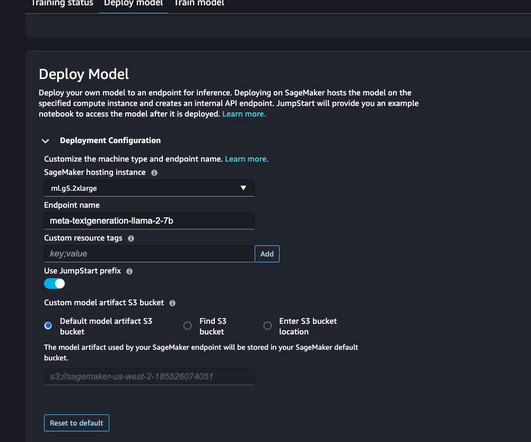
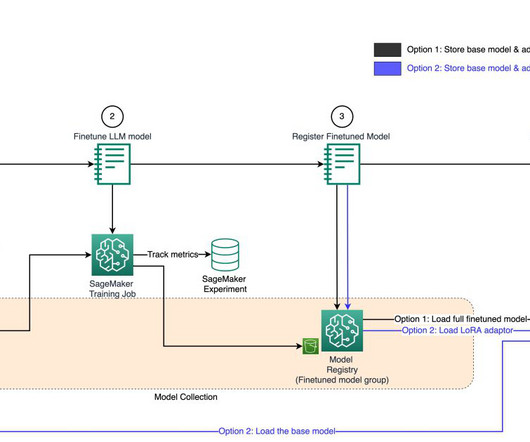
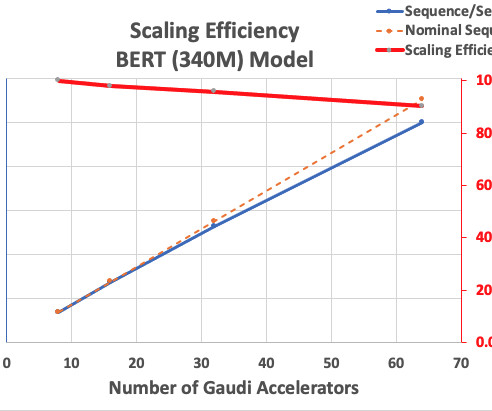
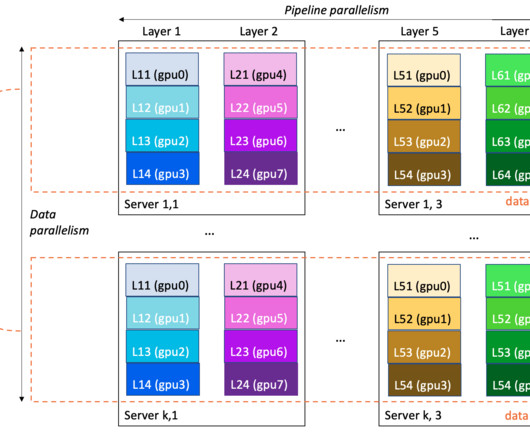
M tokens/$) trained such models with AWS Trainium without losing any model quality. To establish the proof-of-concept and quick reproduction, we’ll use a smaller Wikipedia dataset subset tokenized using GPT2 Byte-pair encoding (BPE) tokenizer. The pricing of trn1.32xl is based on the 3-year reserved effective per hour rate.
















Let's personalize your content