

Bigram Language Modeling From Scratch
Towards AI
FEBRUARY 5, 2024
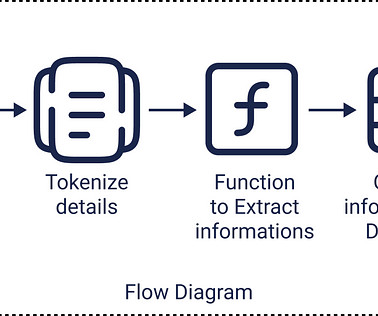
The probability of a word sequence (W = w_1, w_2, …, w_n) is represented as follows: P(W) = P(w_1, w_2,, w_n) ≈ P(w_1) * P(w_2 U+007C w_1) * P(w_3 U+007C w_2) *. * P(w_n U+007C w_{n-1}) Where: P(w_1) is the probability of the first word in the sequence.






































Let's personalize your content