
Predicting Race from Twitter: Unveiling Insights with pyCaret and Machine Learning
Mlearning.ai
JULY 4, 2023
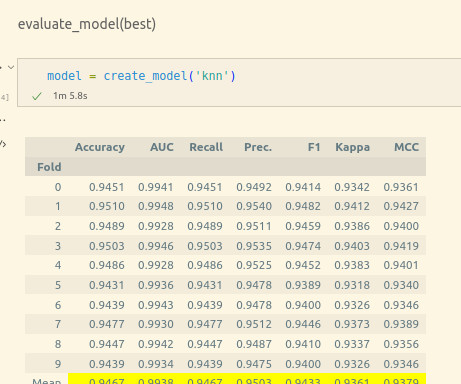
One such intriguing aspect is the potential to predict a user’s race based on their tweets, a task that merges the realms of Natural Language Processing (NLP), machine learning, and sociolinguistics. This allowed us to gain rapid insights into the dataset, paving the way for model selection and evaluation.

















Let's personalize your content