

Build a multilingual automatic translation pipeline with Amazon Translate Active Custom Translation
AWS Machine Learning Blog
JUNE 15, 2023
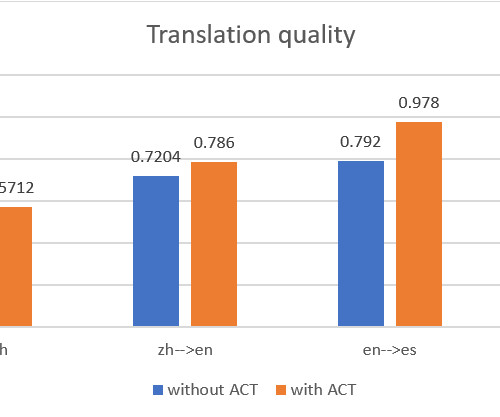
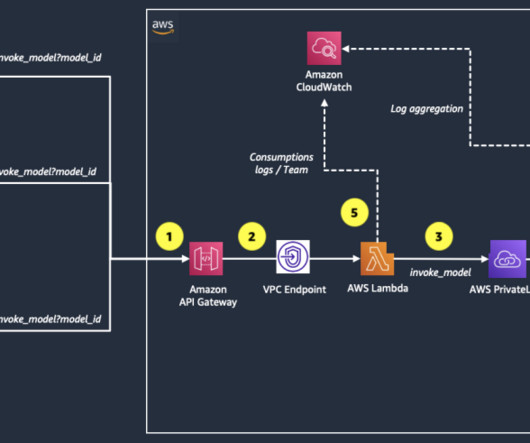
In the following sections, we demonstrate how to build each translation pipeline using Amazon Translate with ACT, along with Amazon SageMaker and Amazon Simple Storage Service (Amazon S3). The following example is extracted from D2L-en book and D2L-zh book. The following screenshot shows an example of a CSV input file.








Let's personalize your content