

RO-ViT: Region-aware pre-training for open-vocabulary object detection with vision transformers
Google Research AI blog
AUGUST 28, 2023
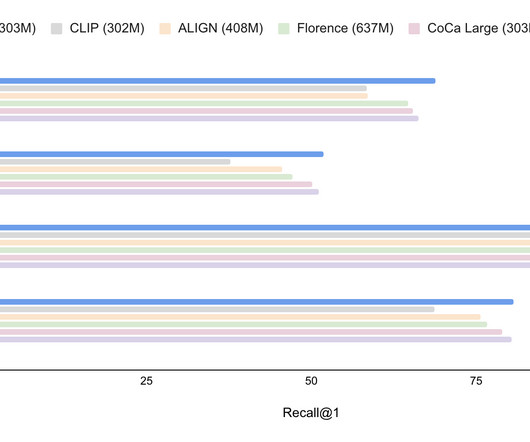
However, as VLMs are primarily designed for image-level tasks like classification and retrieval, they do not fully leverage the concept of objects or regions during the pre-training phase. Region-aware image-text pre-training Existing VLMs are trained to match an image as a whole to a text description.














Let's personalize your content