


Document Information Extraction Using Pix2Struct
Analytics Vidhya
APRIL 26, 2023
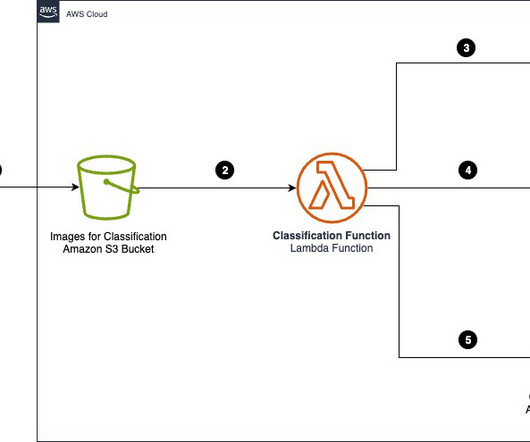
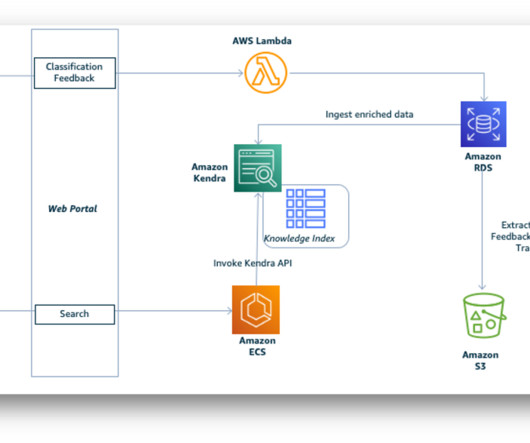
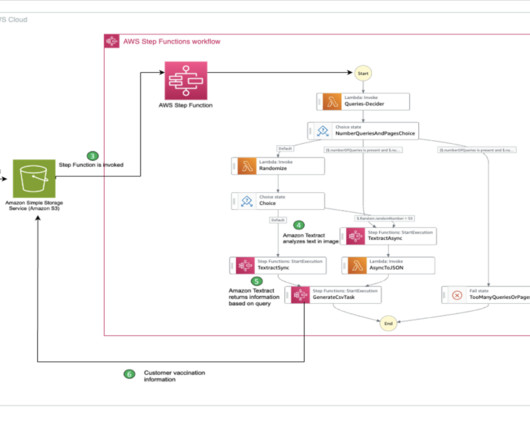
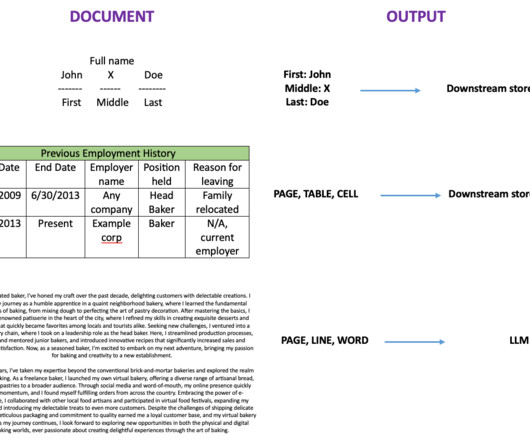
Introduction Document information extraction involves using computer algorithms to extract structured data (like employee name, address, designation, phone number, etc.) from unstructured or semi-structured documents, such as reports, emails, and web pages.
































Let's personalize your content