

Build financial search applications using the Amazon Bedrock Cohere multilingual embedding model
AWS Machine Learning Blog
JANUARY 12, 2024
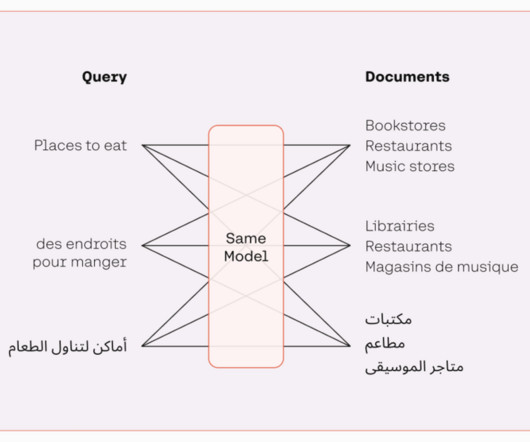
Solution overview Financial analysts need to digest a lot of content, such as financial publications and news media, in order to stay informed. Establish Cohere client co = cohere_aws.Client(mode=cohere_aws.Mode.BEDROCK) model_id = "cohere.embed-multilingual-v3" # Embed documents docs = top_80_df['text'].to_list()













Let's personalize your content