

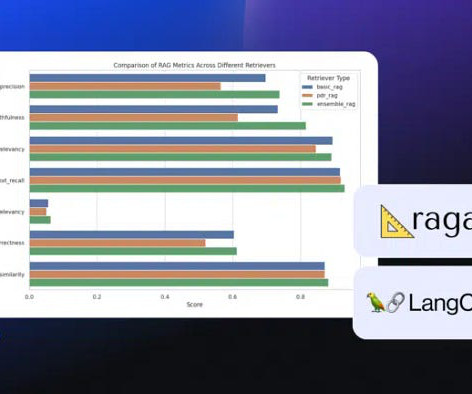
Evaluating RAG Metrics Across Different Retrieval Methods
Towards AI
FEBRUARY 3, 2024
LangChain Docs This text splitter takes a list of characters. from langchain.text_splitter import RecursiveCharacterTextSplitterfrom langchain_community.vectorstores import Chromafrom langchain_community.embeddings import HuggingFaceBgeEmbeddingsmodel_name = "BAAI/bge-large-en-v1.5"encode_kwargs Now, to give it a test!



















Let's personalize your content