

From Good to Great: Elevating Model Performance through Hyperparameter Tuning
Towards AI
JANUARY 26, 2024
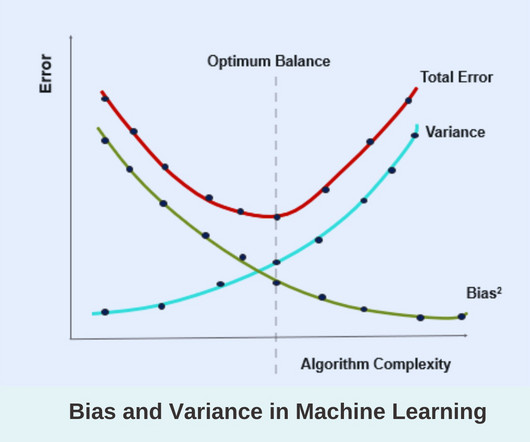
For example, in the training of deep learning models, the weights and biases can be considered as model parameters. For example, in the training of deep learning models, the hyperparameters are the number of layers, the number of neurons in each layer, the activation function, the dropout rate, etc.












Let's personalize your content