

Beginners Guide to Data Warehouse Using Hive Query Language
Analytics Vidhya
APRIL 29, 2022
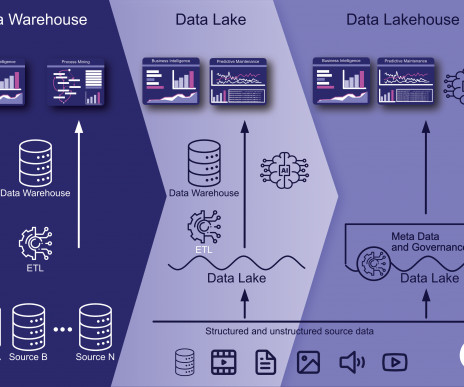
Introduction Have you ever wondered how big IT giants store and process huge amounts of data? Different organizations make use of different databases like an oracle database storing transactional data, MySQL for storing product data, and many others for different tasks. storing the data […].



















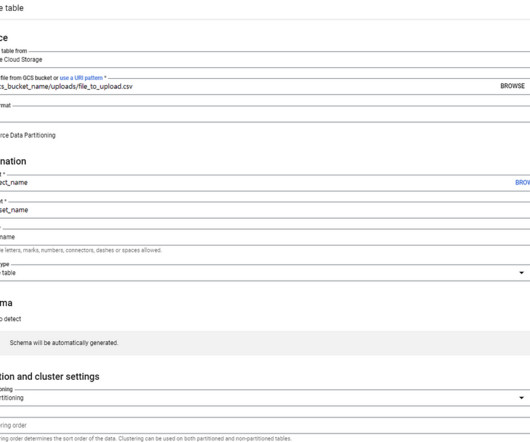









Let's personalize your content