This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
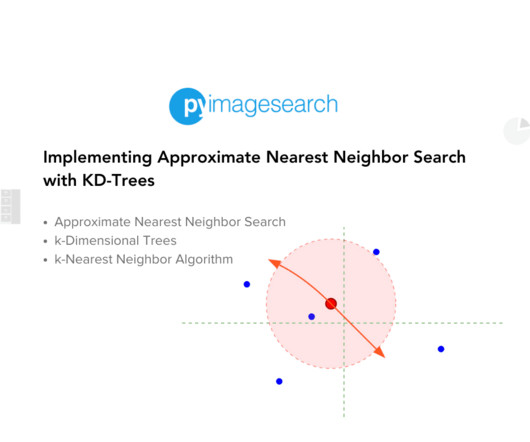
With reaching billions, no hardware can process these operations in a definite amount of time. We will start by setting up libraries and datapreparation. Setup and DataPreparation For implementing a similar word search, we will use the gensim library for loading pre-trained word embeddings vector.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
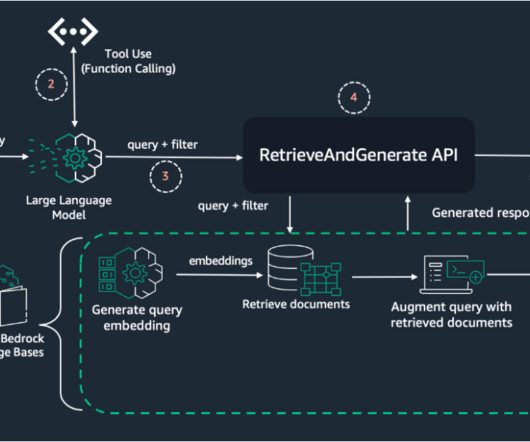
Knowledge base – You need a knowledge base created in Amazon Bedrock with ingested data and metadata. For detailed instructions on setting up a knowledge base, including datapreparation, metadata creation, and step-by-step guidance, refer to Amazon Bedrock Knowledge Bases now supports metadata filtering to improve retrieval accuracy.
For this walkthrough, we use a straightforward generative AI lifecycle involving datapreparation, fine-tuning, and a deployment of Meta’s Llama-3-8B LLM. Datapreparation In this phase, prepare the training and test data for the LLM. We use the SageMaker Core SDK to execute all the steps. tensorrtllm0.11.0-cu124",
Understanding the concept of skew The skew between training and serving datasets can be characterized by several factors, primarily focusing on the differences in distribution and data properties. When training data does not accurately represent the data routine found in deployment, models may struggle to generalize.
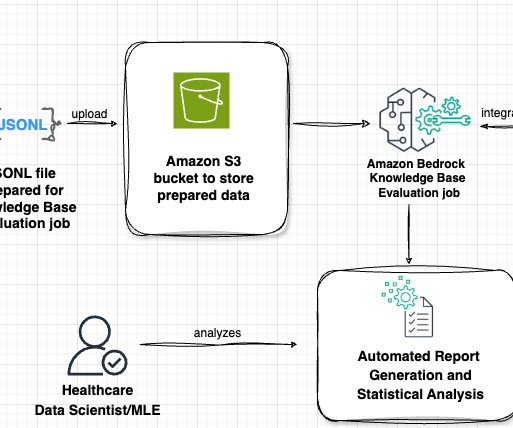
Preparing your data Effective datapreparation is crucial for successful distillation of agent function calling capabilities. Amazon Bedrock provides two primary methods for preparing your training data: uploading JSONL files to Amazon S3 or using historical invocation logs.
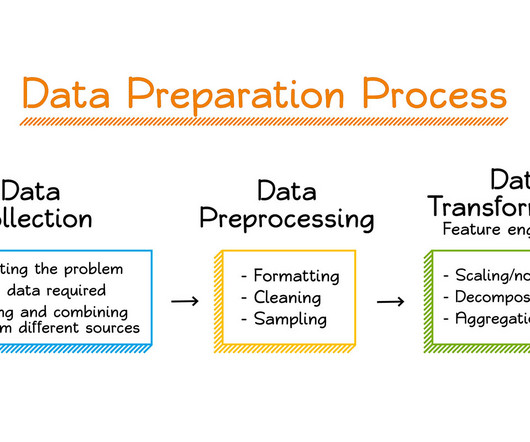
This includes duplicate removal, missing value treatment, variable transformation, and normalization of data. Tools like Python (with pandas and NumPy), R, and ETL platforms like Apache NiFi or Talend are used for datapreparation before analysis.
By identifying patterns within the data, it helps organizations anticipate trends or events, making it a vital component of predictive analytics. Definition and overview of predictive modeling At its core, predictive modeling involves creating a model using historical data that can predict future events.
By utilizing algorithms and statistical models, data mining transforms raw data into actionable insights. The data mining process The data mining process is structured into four primary stages: data gathering, datapreparation, data mining, and data analysis and interpretation.
We use Amazon SageMaker Pipelines , which helps automate the different steps, including datapreparation, fine-tuning, and creating the model. We demonstrated an end-to-end solution that uses SageMaker Pipelines to orchestrate the steps of datapreparation, model training, evaluation, and deployment.
If you are targeting roles involving data visualization , Data Analysis , or Business Intelligence , you can expect your interview to include questions specifically testing your data viz prowess. Preparing for these questions is crucial. The approach depends on the context and the amount of missing data.
Lets examine the key components of this architecture in the following figure, following the data flow from left to right. The workflow consists of the following phases: Datapreparation Our evaluation process begins with a prompt dataset containing paired radiology findings and impressions. No definite pneumonia.
This approach was use case-specific and required datapreparation and manual work. The chain-of-thought prompting technique guides the LLMs to break down a problem into a series of intermediate steps or reasoning steps, explicitly expressing their thought process before arriving at a definitive answer or output.
Definition and functionality of LLM app platforms These platforms encompass various capabilities specifically tailored for LLM development. Data cleaning and annotation Data cleaning: Involves standardizing text and eliminating any unnecessary formatting. KLU.ai: Offers no-code solutions for smooth data source integration.
However, you can also test this by using the Custom project profile by selecting specific blueprints such as LakehouseCatalog and LakeHouseDatabase for scenarios where the business unit doesnt have their own data warehouse. Solution walkthrough (Scenario 1) The first step focuses on preparing the data for each data source for unified access.
It helps business owners and decision-makers choose the right technique based on the type of data they have and the outcome they want to achieve. Let us now look at the key differences starting with their definitions and the type of data they use. In this case, every data point has both input and output values already defined.
For example, services like S3, API Gateway, and Kinesis can trigger processes as soon as new data is detected. AWS Lambda functions perform datapreparation tasks such as cleaning and transforming data before moving on to the inference stage.
Data science is an interdisciplinary field that utilizes advanced analytics techniques to extract meaningful insights from vast amounts of data. This helps facilitate data-driven decision-making for businesses, enabling them to operate more efficiently and identify new opportunities.
This entails breaking down the large raw satellite imagery into equally-sized 256256 pixel chips (the size that the mode expects) and normalizing pixel values, among other datapreparation steps required by the GeoFM that you choose. This routine can be conducted at scale using an Amazon SageMaker AI processing job.
If we have a project that is well-suited to your skillset, I will definitely be reaching out! reply hubraumhugo 9 hours ago | prev | next [–] Kadoa | Multiple Roles (Senior Software Eng, Frontend/UX) | Remote | Full-Time | https://kadoa.com We're building AI agents for unstructured data.
Machine learning algorithms are specialized computational models designed to analyze data, recognize patterns, and make informed predictions or decisions. They leverage statistical techniques to enable machines to learn from previous experiences, refining their approaches as they encounter new data.
Datapreparation is a critical step in any data-driven project, and having the right tools can greatly enhance operational efficiency. Amazon SageMaker Data Wrangler reduces the time it takes to aggregate and prepare tabular and image data for machine learning (ML) from weeks to minutes.
Data, is therefore, essential to the quality and performance of machine learning models. This makes datapreparation for machine learning all the more critical, so that the models generate reliable and accurate predictions and drive business value for the organization. Why do you need DataPreparation for Machine Learning?
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. RPA uses a graphical user interface (GUI) to interact with applications and websites, while ML uses algorithms and statistical models to analyze data.
Sometimes you might have enough data and want to train a language model like BERT or RoBERTa from scratch. While there are many tutorials about tokenization and on how to train the model, there is not much information about how to load the data into the model. Language models gained popularity in NLP in the recent years.
Simple Random Sampling Definition and Overview Simple random sampling is a technique in which each member of the population has an equal chance of being selected to form the sample. Analyze the obtained sample data. Analyze the obtained sample data. Collect data from individuals within the selected clusters.
In other words, companies need to move from a model-centric approach to a data-centric approach.” – Andrew Ng A data-centric AI approach involves building AI systems with quality data involving datapreparation and feature engineering. Custom transforms can be written as separate steps within Data Wrangler.
A better definition would make use of the directed acyclic graph (DAG) since it may not be a linear process. Figure 4: The ModelOps process [Wikipedia] The Machine Learning Workflow Machine learning requires experimenting with a wide range of datasets, datapreparation, and algorithms to build a model that maximizes some target metric(s).
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing data pipelines. Additionally, Feast promotes feature reuse, so the time spent on datapreparation is reduced greatly. The following figure shows schema definition and model which reference it.
the definitions of the conflicting attributes in the example). The files containing code spans that satisfy the query definition constitute the positive examples for the query. An answer to these semantic queries should identify code spans constituting the answer (e.g., Please refer to the paper or comment for additional information.
Connection definition JSON file When connecting to different data sources in AWS Glue, you must first create a JSON file that defines the connection properties—referred to as the connection definition file. The following is a sample connection definition JSON for Snowflake.
Common Pitfalls in LLM Development Neglecting DataPreparation: Poorly prepareddata leads to subpar evaluation and iterations, reducing generalizability and stakeholder confidence. Real-world applications often expose gaps that proper datapreparation could have preempted. Evaluation: Tools likeNotion.
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. The only new line of code is the ProcessingStep after the steps’ definition, which allows us to take the processing job configuration and include it as a pipeline step.
Amazon SageMaker Data Wrangler reduces the time it takes to collect and preparedata for machine learning (ML) from weeks to minutes. We are happy to announce that SageMaker Data Wrangler now supports using Lake Formation with Amazon EMR to provide this fine-grained data access restriction. compute.internal.
No single source of truth: There may be multiple versions or variations of similar data sets, but which is the trustworthy data set users should default to? Missing datadefinitions and formulas: People need to understand exactly what the data represents, in the context of the business, to use it effectively.
No single source of truth: There may be multiple versions or variations of similar data sets, but which is the trustworthy data set users should default to? Missing datadefinitions and formulas: People need to understand exactly what the data represents, in the context of the business, to use it effectively.
In the following sections, we break down the datapreparation, model experimentation, and model deployment steps in more detail. Datapreparation Scalable Capital uses a CRM tool for managing and storing email data. Relevant email contents consist of subject, body, and the custodian banks.
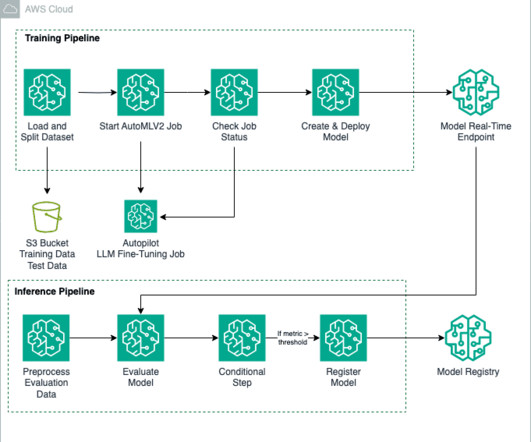
SageMaker AutoMLV2 is part of the SageMaker Autopilot suite, which automates the end-to-end machine learning workflow from datapreparation to model deployment. Datapreparation The foundation of any machine learning project is datapreparation.
Figure 1: LLaVA architecture Preparedata When it comes to fine-tuning the LLaVA model for specific tasks or domains, datapreparation is of paramount importance because having high-quality, comprehensive annotations enables the model to learn rich representations and achieve human-level performance on complex visual reasoning challenges.
Shine a light on who or what is using specific data to speed up collaboration or reduce disruption when changes happen. Data modeling. Leverage semantic layers and physical layers to give you more options for combining data using schemas to fit your analysis. Datapreparation.
This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling. A quick search on the Internet provides multiple definitions by technology-leading companies such as IBM, Amazon, and Oracle.
Shine a light on who or what is using specific data to speed up collaboration or reduce disruption when changes happen. Data modeling. Leverage semantic layers and physical layers to give you more options for combining data using schemas to fit your analysis. Datapreparation.
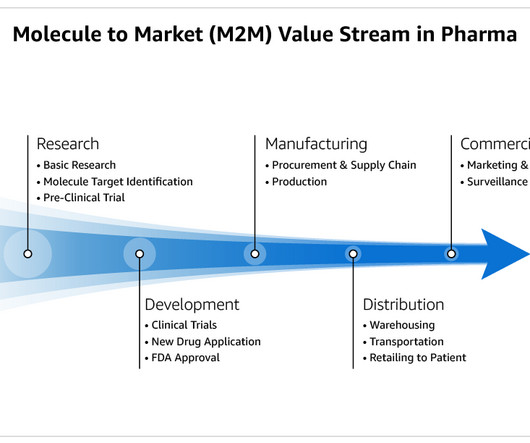
We can define an AI Engineering Process or AI Process (AIP) which can be used to solve almost any AI problem [5][6][7][9]: Define the problem: This step includes the following tasks: defining the scope, value definition, timelines, governance, and resources associated with the deliverable.
Definition and purpose of RPA Robotic process automation refers to the use of software robots to automate rule-based business processes. RPA uses a graphical user interface (GUI) to interact with applications and websites, while ML uses algorithms and statistical models to analyze data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















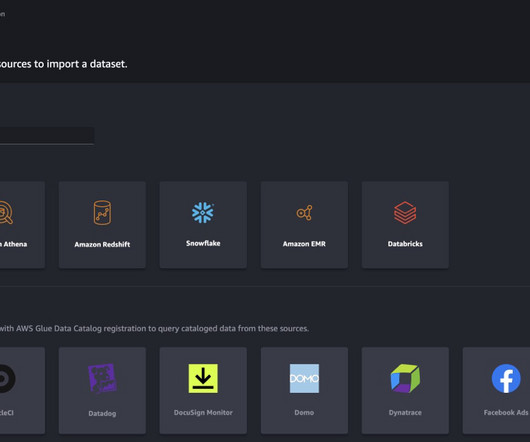




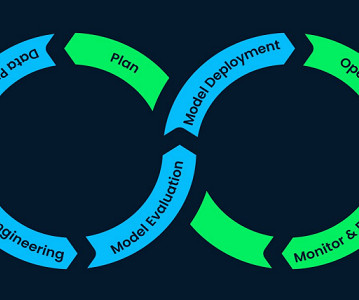
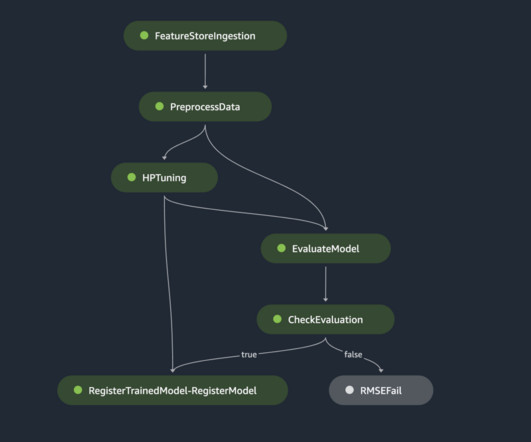

















Let's personalize your content