

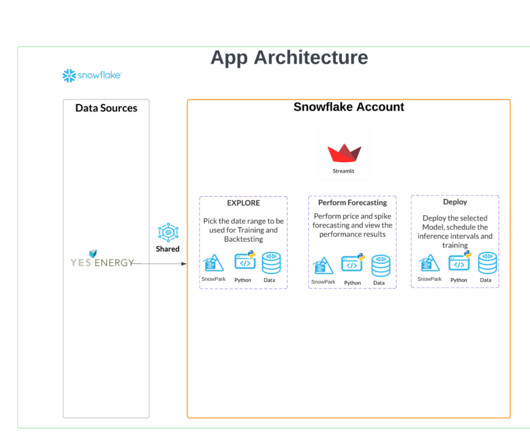
Dynamic SQL Queries to Transform Data
Analytics Vidhya
JUNE 28, 2022
. “Preponderance data opens doorways to complex and Avant analytics.” ” Introduction to SQL Queries Data is the premium product of the 21st century. Enterprises are focused on data stockpiling because more data leads to meticulous and calculated decision-making and opens more doors for business […].










































Let's personalize your content