This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
To drive real AI-powered innovation, you need to deliver location data (and all enterprise data) where it’s needed – quickly, securely, and reliably. A modern integration strategy lets you design pipelines wherever your data resides – whether on-premises, in the cloud, or across hybrid environments.
Architecture layers The architecture consists of the following layers: Data acquisition layer – This foundation layer features specialized components for social media connectivity across channels like LinkedIn, Twitter, and YouTube, alongside sophisticated web scraping frameworks with rate limiting and randomization capabilities.
To drive real AI-powered innovation, you need to deliver location data (and all enterprise data) where it’s needed – quickly, securely, and reliably. A modern integration strategy lets you design pipelines wherever your data resides – whether on-premises, in the cloud, or across hybrid environments.
To drive real AI-powered innovation, you need to deliver location data (and all enterprise data) where it’s needed – quickly, securely, and reliably. A modern integration strategy lets you design pipelines wherever your data resides – whether on-premises, in the cloud, or across hybrid environments.
Many organizations store their data in structured formats within data warehouses and datalakes. Amazon Bedrock Knowledge Bases offers a feature that lets you connect your RAG workflow to structured data stores. The key is to choose a solution that can effectively host your database and compute infrastructure.
Each month, ODSC has a few insightful webinars that touch on a range of issues that are important in the data science world, from use cases of machine learning models, to new techniques/frameworks, and more. So here’s a summary of a few recent webinars that you’ll want to watch. Watch on-demand here.
The Future of the Single Source of Truth is an Open DataLake Organizations that strive for high-performance data systems are increasingly turning towards the ELT (Extract, Load, Transform) model using an open datalake. To DIY you need to: host an API, build a UI, and run or rent a database.
During the embeddings experiment, the dataset was converted into embeddings, stored in a vector database, and then matched with the embeddings of the question to extract context. The generated query is then run against the database to fetch the relevant context. Based on the initial tests, this method showed great results.
Guided Navigation Guided navigation helps data stewards locate sensitive data. This includes finding the most exposed sensitive data and ensuring it is used properly. There are many locations where sensitive data can reside — from datalakes, databases, and reports, to APIs and queries.
Building an Effective OSS Management Layer for Your DataLake Ahead of her ODSC West session on OSS management layers, the speaker discusses how datalakes can benefit from this system. Q&A session with NVIDIA Thursday, October 17th, 2024, 01:00 PM Ready to dive into the world of AI innovation?
Alation helps connects to any source Alation helps connect to virtually any data source through pre-built connectors. Alation crawls and indexes data assets stored across disparate repositories, including cloud datalakes, databases, Hadoop files, and data visualization tools. Subscribe to Alation's Blog.
Storage Solutions: Secure and scalable storage options like Azure Blob Storage and Azure DataLake Storage. Key features and benefits of Azure for Data Science include: Scalability: Easily scale resources up or down based on demand, ideal for handling large datasets and complex computations.
Data Version Control for DataLakes: Handling the Changes in Large Scale In this article, we will delve into the concept of datalakes, explore their differences from data warehouses and relational databases, and discuss the significance of data version control in the context of large-scale data management.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





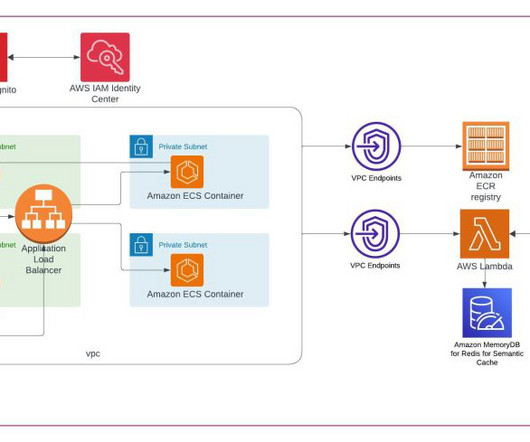

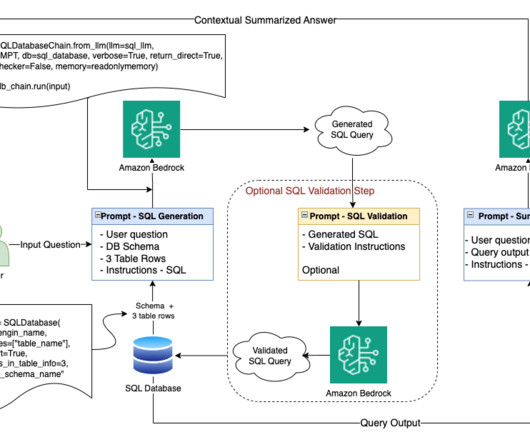




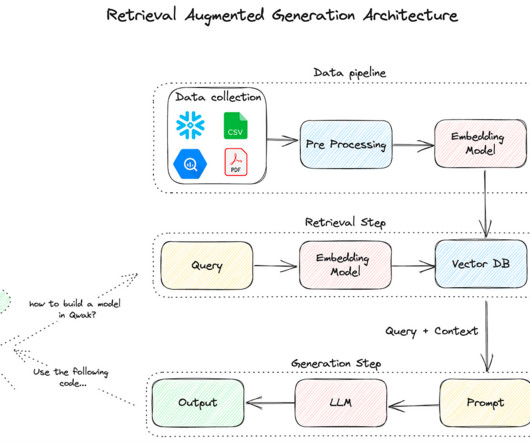






Let's personalize your content