

Turn the face of your business from chaos to clarity
Dataconomy
JULY 28, 2023
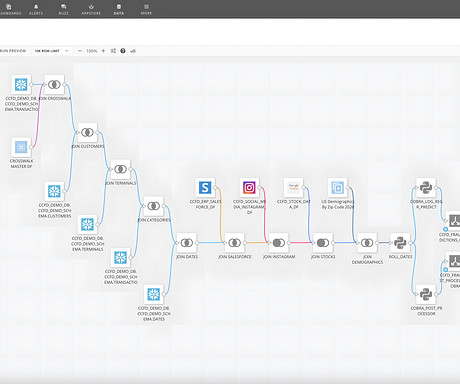
These tools offer a wide range of functionalities to handle complex data preparation tasks efficiently. The tool also employs AI capabilities for automatically providing attribute names and short descriptions for reports, making it easy to use and efficient for data preparation.













Let's personalize your content