
8 Data Lake Vendors to Make Your Data Life Easier in 2023
ODSC - Open Data Science
JUNE 7, 2023
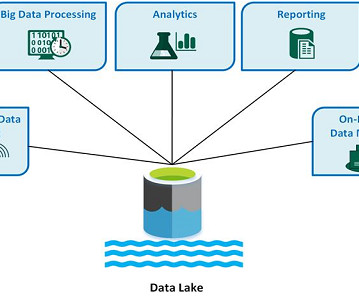
Data has to be stored somewhere. Data warehouses are repositories for your cleaned, processed data, but what about all that unstructured data your organization is starting to notice? What is a data lake? This can be structured, semi-structured, and even unstructured data. Where does it go?











Let's personalize your content