

Data Science Project?—?Predictive Modeling on Biological Data
Mlearning.ai
FEBRUARY 15, 2024
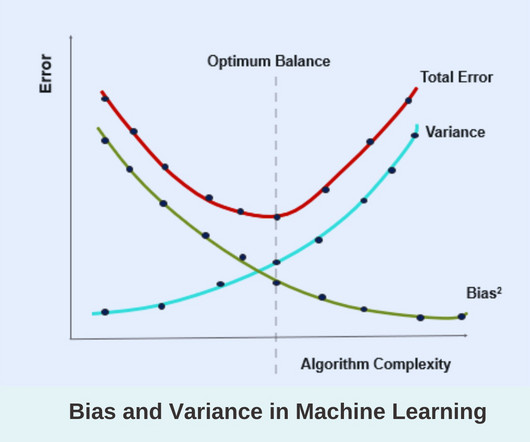
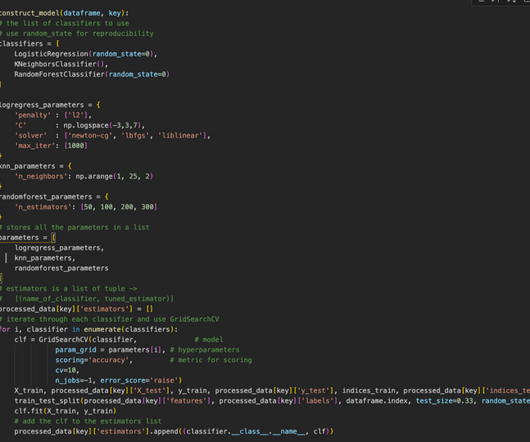
Data Science Project — Predictive Modeling on Biological Data Part III — A step-by-step guide on how to design a ML modeling pipeline with scikit-learn Functions. Many ML optimizing functions assume that data has variance in the same order that means it is centered around 0. You can refer part-I and part-II of this article.











Let's personalize your content