


The Semantic Lakehouse Explained
Dataversity
MARCH 6, 2023
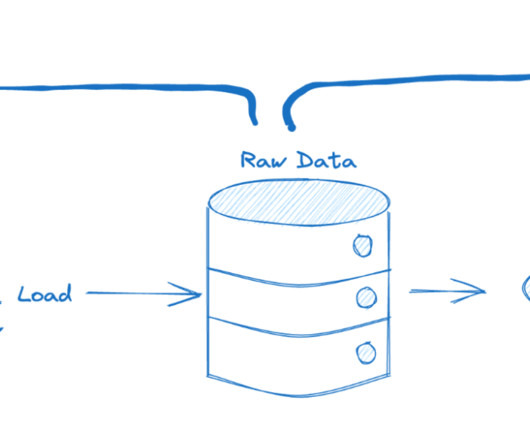
Data lakes and semantic layers have been around for a long time – each living in their own walled gardens, tightly coupled to fairly narrow use cases. As data and analytics infrastructure migrates to the cloud, many are challenging how these foundational technology components fit in the modern data and analytics stack.







































Let's personalize your content