

23 Best Free NLP Datasets for Machine Learning
Iguazio
SEPTEMBER 20, 2023
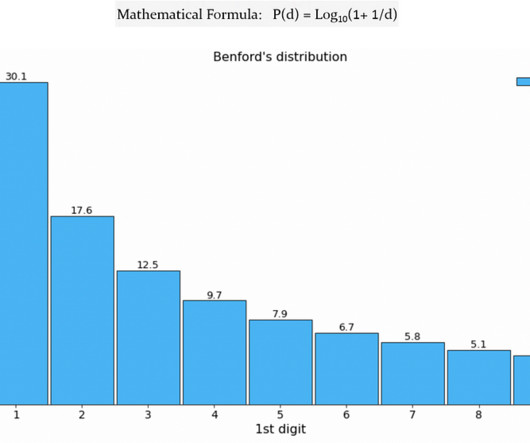
The list is divided into a number of groups and types: Q&A Reviews and Ratings Sentiment Analysis Synonyms Emails Long-form Content Audio You can use these datasets for a number of use cases, like creating personal assistants, automating customer service, language translation, and more. 1,473 sentences were labeled as answer sentences.



























Let's personalize your content