

Enhancing Data Fabric with SQL Asset Type in IBM Knowledge Catalog
IBM Data Science in Practice
APRIL 26, 2024
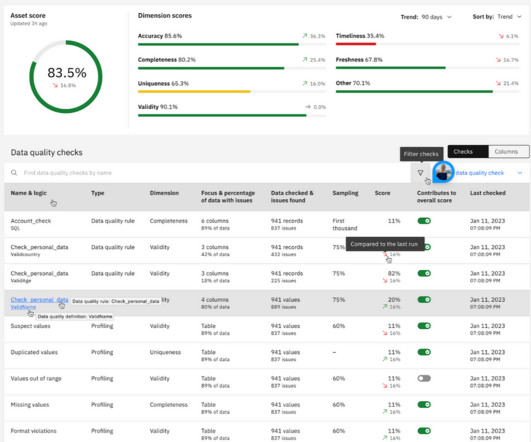
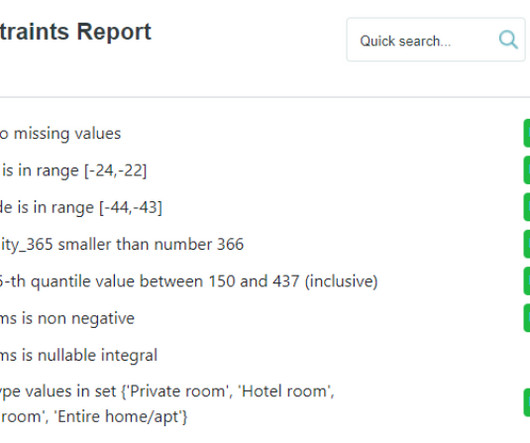
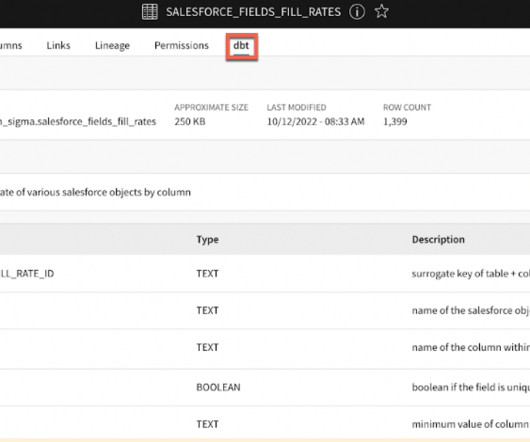
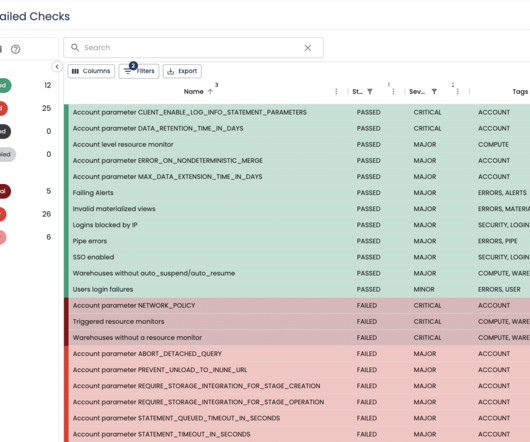
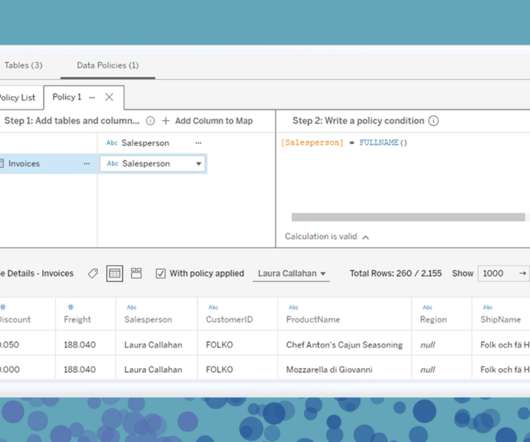
In this blog, we explore how the introduction of SQL Asset Type enhances the metadata enrichment process within the IBM Knowledge Catalog , enhancing data governance and consumption. Introducing SQL Asset Type A significant enhancement to the metadata enrichment process is the introduction of SQL Asset Type.


























Let's personalize your content