


Why optimize your warehouse with a data lakehouse strategy
IBM Journey to AI blog
APRIL 25, 2023
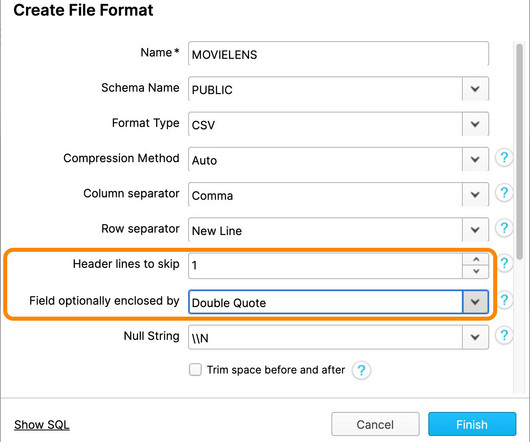
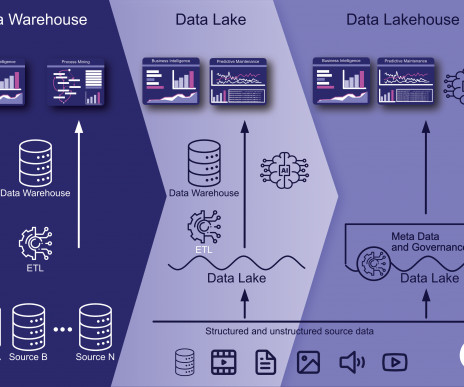
In a prior blog , we pointed out that warehouses, known for high-performance data processing for business intelligence, can quickly become expensive for new data and evolving workloads. To do so, Presto and Spark need to readily work with existing and modern data warehouse infrastructures.











Let's personalize your content