This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
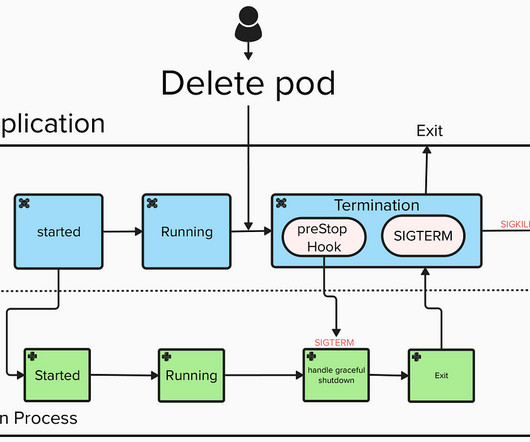
Graceful External Termination: Handling Pod Deletions in Kubernetes Data Ingestion and Streaming Jobs When running big-data pipelines in Kubernetes, especially streaming jobs, its easy to overlook how these jobs deal with termination. If not handled correctly, this can lead to locks, data issues, and a negative user experience.
The magic of the data warehouse was figuring out how to get data out of these transactional systems and reorganize it in a structured way optimized for analysis and reporting. But those end users werent always clear on which data they should use for which reports, as the datadefinitions were often unclear or conflicting.
Data Storage and Management Once data have been collected from the sources, they must be secured and made accessible. The responsibilities of this phase can be handled with traditional databases (MySQL, PostgreSQL), cloud storage (AWS S3, Google Cloud Storage), and bigdata frameworks (Hadoop, Apache Spark).
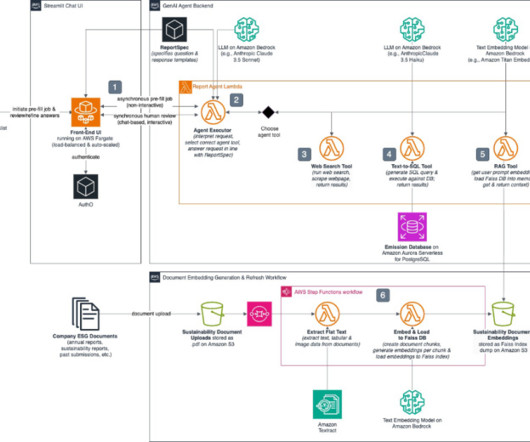
This ReportSpec definition is inserted into the task prompt. Christian Dunn is a Software Engineer based in London building ETL pipelines, web-apps, and other business solutions at Gardenia Technologies. She helps AWS customers to bring their big ideas to life and accelerate the adoption of emerging technologies.
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
I'm JD, a Software Engineer with experience touching many parts of the stack (frontend, backend, databases, data & ETL pipelines, you name it). With over 3 years of working with ETL pipelines and REST API integrations and development, I understand how to develop and maintain robust and scalable data systems.
Database replication involves creating copies of data across different servers or databases, which ensures that all users and applications have access to the same data at all times. This practice is vital in distributed database systems and enables organizations to manage data more effectively.
- a beginner question Let’s start with the basic thing if I talk about the formal definition of Data Science so it’s like “Data science encompasses preparing data for analysis, including cleansing, aggregating, and manipulating the data to perform advanced data analysis” , is the definition enough explanation of data science?
Summary: HDFS in BigData uses distributed storage and replication to manage massive datasets efficiently. By co-locating data and computations, HDFS delivers high throughput, enabling advanced analytics and driving data-driven insights across various industries. It fosters reliability. between 2024 and 2030.
Summary: Choosing the right ETL tool is crucial for seamless data integration. Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Choosing the right ETL tool is crucial for smooth data management.
While growing data enables companies to set baselines, benchmarks, and targets to keep moving ahead, it poses a question as to what actually causes it and what it means to your organization’s engineering team efficiency. What’s causing the data explosion? Bigdata analytics from 2022 show a dramatic surge in information consumption.
Data warehouse architecture The data warehouse architecture is a very critical concept regarding bigdata. It could be defined as the layout and design of a data warehouse, which at other times could act as a central repository for all organization’s data.
In the ever-evolving world of bigdata, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Unlike traditional data warehouses or relational databases, data lakes accept data from a variety of sources, without the need for prior data transformation or schema definition.
An example direct acyclic graph (DAG) might automate data ingestion, processing, model training, and deployment tasks, ensuring that each step is run in the correct order and at the right time. Though it’s worth mentioning that Airflow isn’t used at runtime as is usual for extract, transform, and load (ETL) tasks.
A typical modern data stack consists of the following: A data warehouse. Data ingestion/integration services. Reverse ETL tools. Data orchestration tools. These tools are used to manage bigdata, which is defined as data that is too large or complex to be processed by traditional means.
Let’s delve into the key components that form the backbone of a data warehouse: Source Systems These are the operational databases, CRM systems, and other applications that generate the raw data feeding the data warehouse. Data Extraction, Transformation, and Loading (ETL) This is the workhorse of architecture.
Our customers wanted the ability to connect to Amazon EMR to run ad hoc SQL queries on Hive or Presto to query data in the internal metastore or external metastore (such as the AWS Glue Data Catalog ), and prepare data within a few clicks. internal in the certificate subject definition. compute.internal.
I started working in Data Science right after graduating with an MS degree in Electrical and Computer Engineering from the University of California, Los Angeles (UCLA). You might even need to write custom data crawling code, find public datasets, and find pragmatic ways to augment data to solve the problem.
Metric Definition Example Score True Positive (TP) The number of words in the model output that are also contained in the ground truth. By this definition, we recommend interpreting precision scores as a measure of conciseness to the ground truth. By assessing exact matching, the Exact Match and Quasi-Exact Match metrics are returned.
Data fabric is now on the minds of most data management leaders. In our previous blog, Data Mesh vs. Data Fabric: A Love Story , we defined data fabric and outlined its uses and motivations. The data catalog is a foundational layer of the data fabric. ” 1.
Here are some challenges you might face while managing unstructured data: Storage consumption: Unstructured data can consume a large volume of storage. For instance, if you are working with several high-definition videos, storing them would take a lot of storage space, which could be costly. Unstructured.io
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



























Let's personalize your content