This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Classic compute (workflows, Declarative Pipelines, SQL Warehouse, etc.) inherits tags on the cluster definition, while serverless adheres to Serverless Budget Policies ( AWS | Azure | GCP ). In general, you can add tags to two kinds of resources: Compute Resources: Includes SQL Warehouse, jobs, instance pools, etc.
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both data lakes and datawarehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
It gives these users a single, intuitive entry point to interact with data and AI—without needing to understand clusters, queries, models, or notebooks. Databricks One is a new product experience designed specifically for business users.
Instead of running on a fixed schedule, maintenance now adapts to workload patterns and data layout to optimize cost and performance automatically. This reduces unnecessary rewrites, improving performance and lowering compute costs by avoiding full file rewrites during updates and deletes.
Whether you’re running small-scale analytics or managing enterprise-level datawarehouses, these tips will help drive performance and meaningful business outcomes for your organization. Storage Costs Our first tip involves taking a closer look at managing how your data is stored, organized, and accessed.
In this post, we will be particularly interested in the impact that cloud computing left on the modern datawarehouse. We will explore the different options for data warehousing and how you can leverage this information to make the right decisions for your organization. Understanding the Basics What is a DataWarehouse?
Versioning also ensures a safer experimentation environment, where data scientists can test new models or hypotheses on historical data snapshots without impacting live data. Note : Cloud Datawarehouses like Snowflake and Big Query already have a default time travel feature. FAQs What is a Data Lakehouse?
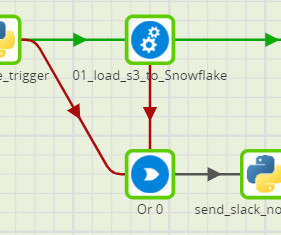
Understanding Matillion and Snowflake, the Python Component, and Why it is Used Matillion is a SaaS-based data integration platform that can be hosted in AWS, Azure, or GCP and supports multiple cloud datawarehouses.
On a lightweight four-node cluster, the TTR and TTS analyses completed in 5 and 40 minutes respectively on the network described above (1,700 nodes)—all for under $10 in cloud spend. This highlights the solution’s impressive speed and cost-effectiveness.
AzureData Studio has rapidly gained popularity among developers and database administrators for its user-friendly design and powerful features. As a versatile tool, it simplifies the management of both SQL Server and Azure SQL databases, offering a modern alternative to traditional database management solutions.
Apache Hadoop Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets across clusters of computers using simple programming models. Key Features : Scalability : Hadoop can handle petabytes of data by adding more nodes to the cluster. Statistics Kafka handles over 1.1
We are ClickHouse Inc, the company behind the database aiming to build the best in class real time datawarehouse. We also maintain our own ClickHouse-based Data Infrastructure. But if your issue is suffered by many but you don't all cluster together in latitude and longitude then that issue has less weight.
Azure Synapse provides a unified platform to ingest, explore, prepare, transform, manage, and serve data for BI (Business Intelligence) and machine learning needs. DWUs (DataWarehouse Units) can customize resources and optimize performance and costs.
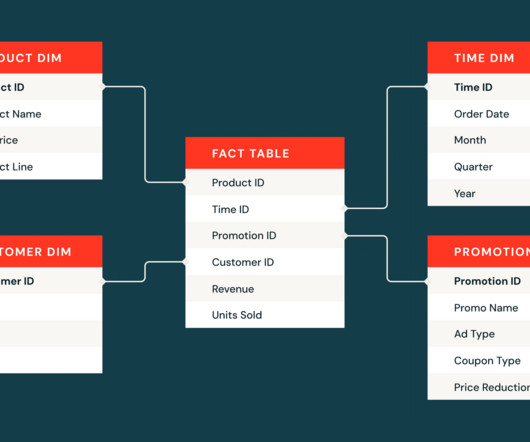
A datawarehouse is a centralized repository designed to store and manage vast amounts of structured and semi-structured data from multiple sources, facilitating efficient reporting and analysis. Begin by determining your data volume, variety, and the performance expectations for querying and reporting.
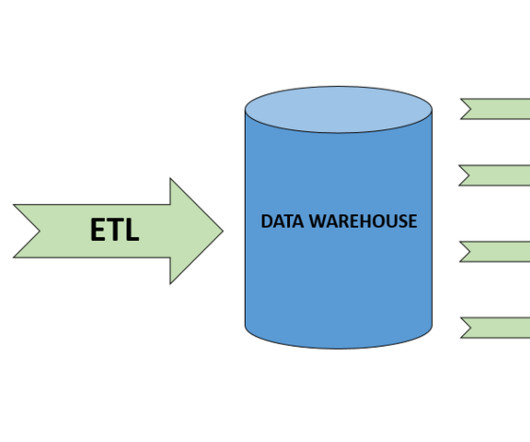
The ETL process is defined as the movement of data from its source to destination storage (typically a DataWarehouse) for future use in reports and analyzes. The data is initially extracted from a vast array of sources before transforming and converting it to a specific format based on business requirements.
The ultimate need for vast storage spaces manifests in datawarehouses: specialized systems that aggregate data coming from numerous sources for centralized management and consistency. In this article, you’ll discover what a Snowflake datawarehouse is, its pros and cons, and how to employ it efficiently.
Data is at the core of any ML project, so data infrastructure is a foundational concern. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing datawarehouses. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch.
Role of Data Engineers in the Data Ecosystem Data Engineers play a crucial role in the data ecosystem by bridging the gap between raw data and actionable insights. They are responsible for building and maintaining data architectures, which include databases, datawarehouses, and data lakes.
Also Read: Top 10 Data Science tools for 2024. It is a process for moving and managing data from various sources to a central datawarehouse. This process ensures that data is accurate, consistent, and usable for analysis and reporting. This process helps organisations manage large volumes of data efficiently.
It acts as a catalogue, providing information about the structure and location of the data. · Hive Query Processor It translates the HiveQL queries into a series of MapReduce jobs. · Hive Execution Engine It executes the generated query plans on the Hadoop cluster. It manages the execution of tasks across different environments.
Snowflake stores and manages data in the cloud using a shared disk approach, which simplifies data management. The shared-nothing architecture ensures that users don’t have to worry about distributing data across multiple cluster nodes. They are flexible, secure, and provide exceptional performance.
I would perform exploratory data analysis to understand the distribution of customer transactions and identify potential segments. Then, I would use clustering techniques such as k-means or hierarchical clustering to group customers based on similarities in their purchasing behaviour. What approach would you take?
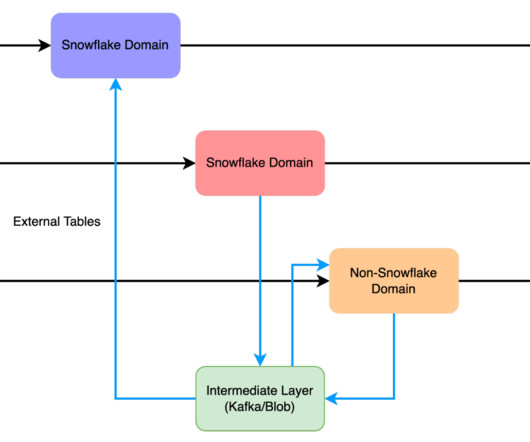
A data mesh is a conceptual architectural approach for managing data in large organizations. Traditional data management approaches often involve centralizing data in a datawarehouse or data lake, leading to challenges like data silos, data ownership issues, and data access and processing bottlenecks.
Model Development Data Scientists develop sophisticated machine-learning models to derive valuable insights and predictions from the data. These models may include regression, classification, clustering, and more. They work with databases and datawarehouses to ensure data integrity and security.
Word2Vec , GloVe , and BERT are good sources of embedding generation for textual data. These capture the semantic relationships between words, facilitating tasks like classification and clustering within ETL pipelines. Multimodal embeddings help combine unstructured data from various sources in datawarehouses and ETL pipelines.
Co-location data centers: These are data centers that are owned and operated by third-party providers and are used to house the IT equipment of multiple organizations. Edge data centers: These are data centers that are located closer to the edge of the network, where data is generated and consumed, rather than in central locations.
Second, it leverages container isolation in Databricks’ cluster manager to securely isolate user code from the core Spark engine. Lakeguard builds upon two main components: First, it uses Spark Connect, a JDBC-like execution protocol, to separate the client application from the server and ensure version compatibility.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






























Let's personalize your content