
Accelerate time to business insights with the Amazon SageMaker Data Wrangler direct connection to Snowflake
AWS Machine Learning Blog
JUNE 23, 2023
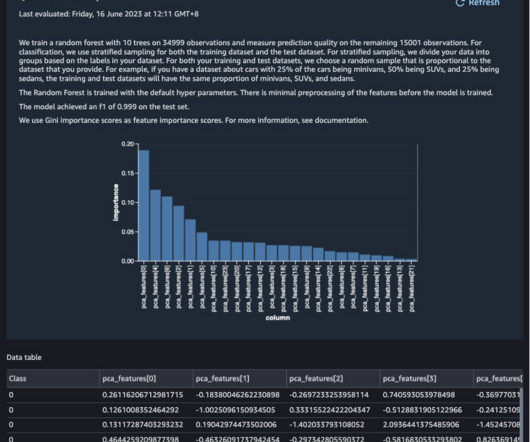
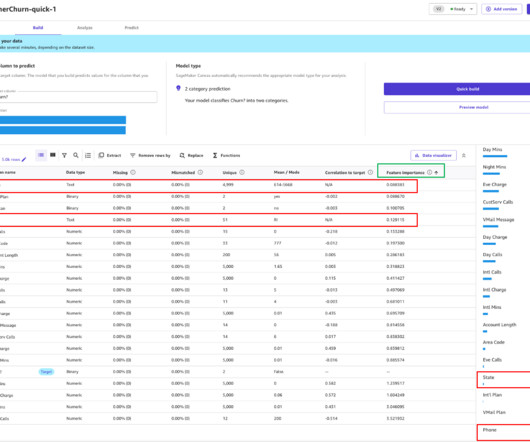
Amazon SageMaker Data Wrangler is a single visual interface that reduces the time required to prepare data and perform feature engineering from weeks to minutes with the ability to select and clean data, create features, and automate data preparation in machine learning (ML) workflows without writing any code.













Let's personalize your content