Build a Serverless News Data Pipeline using ML on AWS Cloud
KDnuggets
NOVEMBER 18, 2021
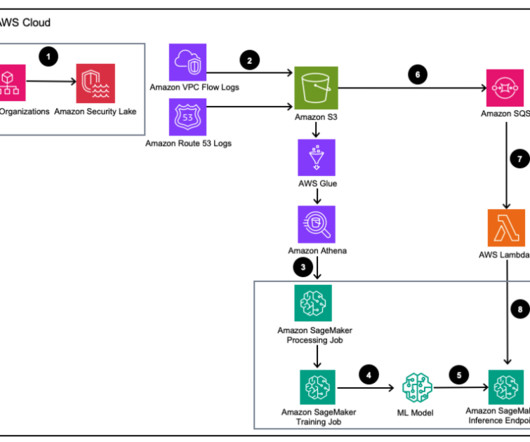
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
 AWS Data Pipeline ML Python
AWS Data Pipeline ML Python 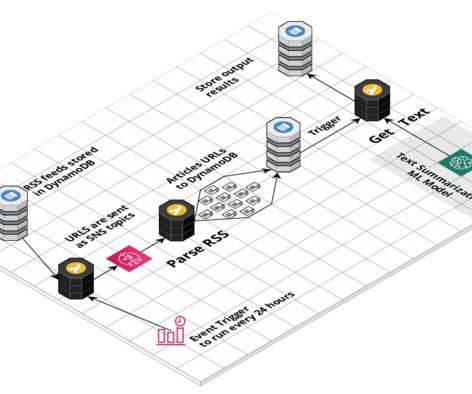
KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

The MLOps Blog
MAY 17, 2023
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Mlearning.ai
APRIL 6, 2023
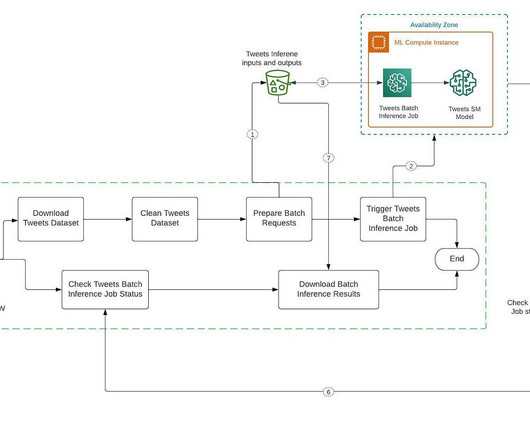
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference data pipeline on large datasets is a challenge many companies face. The Batch job automatically launches an ML compute instance, deploys the model, and processes the input data in batches, producing the output predictions.

NOVEMBER 24, 2023
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.

AWS Machine Learning Blog
MARCH 1, 2023
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
AWS Machine Learning Blog
MARCH 8, 2023
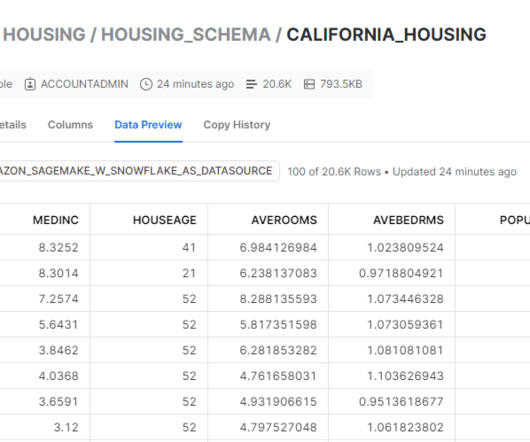
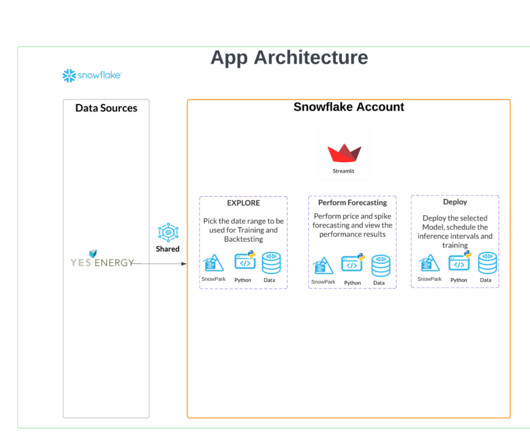
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.

Expert insights. Personalized for you.

























Let's personalize your content