
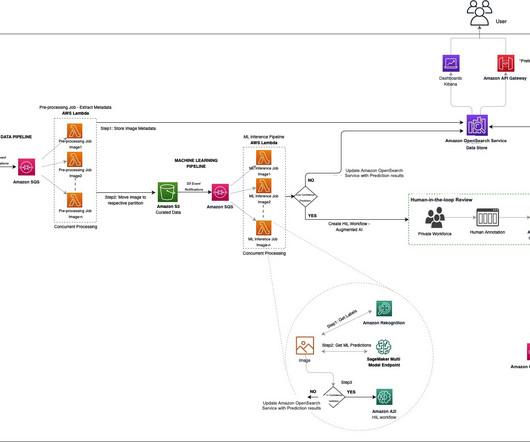
Build a Serverless News Data Pipeline using ML on AWS Cloud
KDnuggets
NOVEMBER 18, 2021
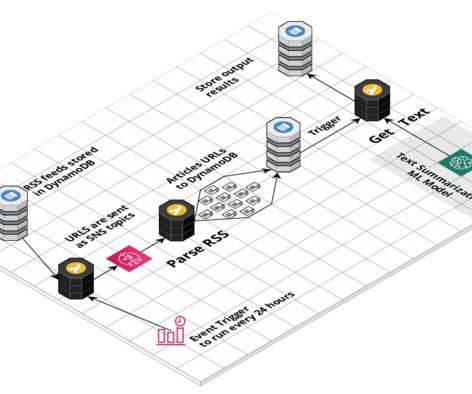
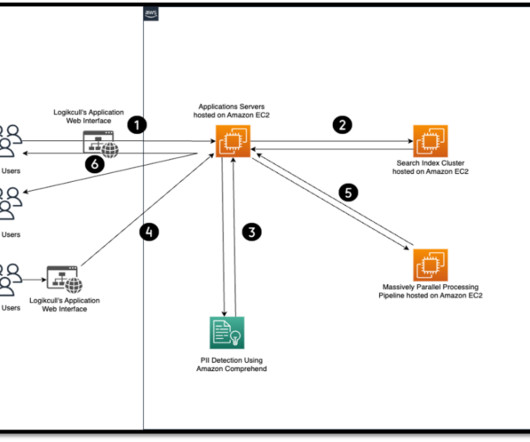
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.

KDnuggets
NOVEMBER 18, 2021
This is the guide on how to build a serverless data pipeline on AWS with a Machine Learning model deployed as a Sagemaker endpoint.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
Analytics Vidhya
FEBRUARY 6, 2023
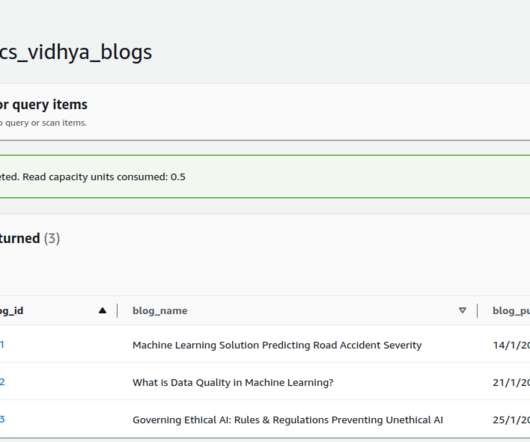
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary. appeared first on Analytics Vidhya.

NOVEMBER 7, 2023
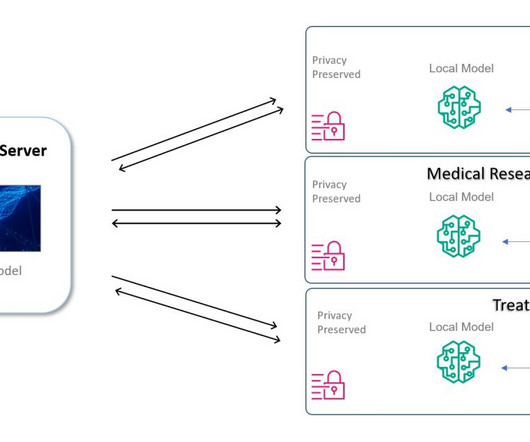
“Data is at the center of every application, process, and business decision,” wrote Swami Sivasubramanian, VP of Database, Analytics, and Machine Learning at AWS, and I couldn’t agree more. A common pattern customers use today is to build data pipelines to move data from Amazon Aurora to Amazon Redshift.

Towards AI
OCTOBER 4, 2023
Photo by Markus Winkler on Unsplash This story explains how to create and orchestrate machine learning pipelines with AWS Step Functions and deploy them using Infrastructure as Code. This article is for data and ML Ops engineers who would want to deploy and update ML pipelines using CloudFormation templates.

Precisely
APRIL 11, 2024
In an era where cloud technology is not just an option but a necessity for competitive business operations, the collaboration between Precisely and Amazon Web Services (AWS) has set a new benchmark for mainframe and IBM i modernization. Solution page Precisely on Amazon Web Services (AWS) Precisely brings data integrity to the AWS cloud.

The MLOps Blog
MAY 17, 2023
Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier. What is an ETL data pipeline in ML? Let’s look at the importance of ETL pipelines in detail.

Expert insights. Personalized for you.



























Let's personalize your content