

Streamlining Data Workflow with Apache Airflow on AWS EC2
Analytics Vidhya
APRIL 23, 2024
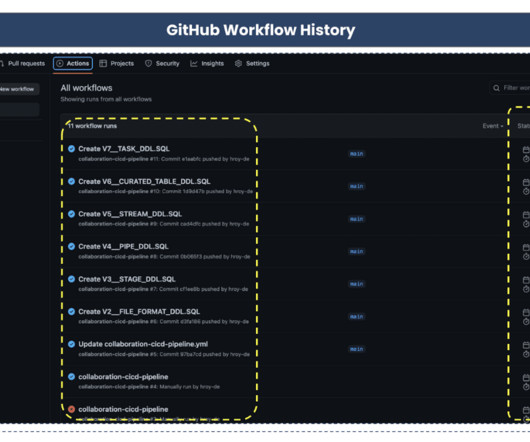
Introduction Apache Airflow is a powerful platform that revolutionizes the management and execution of Extracting, Transforming, and Loading (ETL) data processes. It offers a scalable and extensible solution for automating complex workflows, automating repetitive tasks, and monitoring data pipelines.



























Let's personalize your content