

Integrating AWS Data Lake and RDS MS SQL: A Guide to Writing and Retrieving Data Securely
Dataversity
MARCH 26, 2024
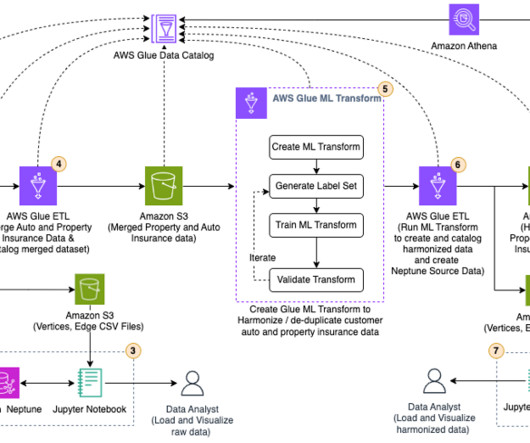
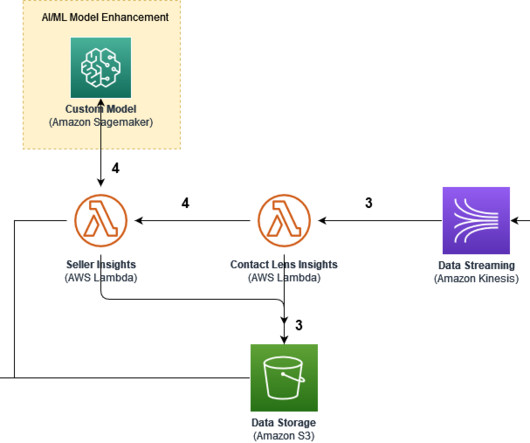
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.



























Let's personalize your content