
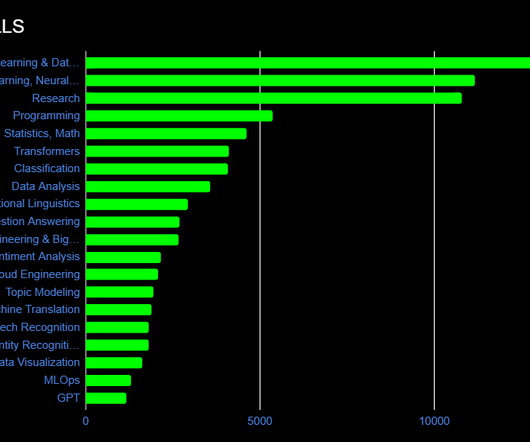
Top NLP Skills, Frameworks, Platforms, and Languages for 2023
ODSC - Open Data Science
FEBRUARY 17, 2023
Developing NLP tools isn’t so straightforward, and requires a lot of background knowledge in machine & deep learning, among others. In a change from last year, there’s also a higher demand for those with data analysis skills as well. Having mastery of these two will prove that you know data science and in turn, NLP.









Let's personalize your content