

Crafting Serverless ETL Pipeline Using AWS Glue and PySpark
Analytics Vidhya
DECEMBER 26, 2022
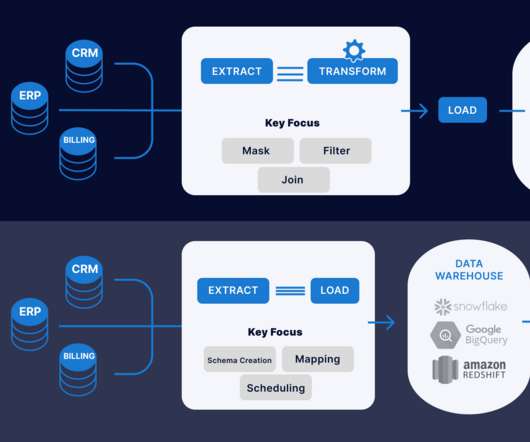
Overview ETL (Extract, Transform, and Load) is a very common technique in data engineering. Traditionally, ETL processes are […]. The post Crafting Serverless ETL Pipeline Using AWS Glue and PySpark appeared first on Analytics Vidhya. This article was published as a part of the Data Science Blogathon.















Let's personalize your content