This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
We will start by setting up libraries and datapreparation. Setup and DataPreparation For implementing a similar word search, we will use the gensim library for loading pre-trained word embeddings vector. My mission is to change education and how complex ArtificialIntelligence topics are taught.
We discuss the important components of fine-tuning, including use case definition, datapreparation, model customization, and performance evaluation. This post dives deep into key aspects such as hyperparameter optimization, data cleaning techniques, and the effectiveness of fine-tuning compared to base models.
Organizations need a unified, streamlined approach that simplifies the entire process from datapreparation to model deployment. To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities.
By Kanwal Mehreen , KDnuggets Technical Editor & Content Specialist on July 7, 2025 in Language Models Image by Author | Canva Large language models are a big step forward in artificialintelligence. They can predict and generate text that sounds like it was written by a human.
This strategic decision was driven by several factors: Efficient datapreparation Building a high-quality pre-training dataset is a complex task, involving assembling and preprocessing text data from various sources, including web sources and partner companies. The team opted for fine-tuning on AWS.
It groups similar data points or identifies outliers without prior guidance. Type of Data Used in Each Approach Supervised learning depends on data that has been organized and labeled. This datapreparation process ensures that every example in the dataset has an input and a known output.
DataPreparation The first step in building the RAG chatbot is to prepare the data. In this case, the data consists of PDF documents, which can be research articles or any other PDF files of your choice. Its recommended to use a virtual environment to manage dependencies and avoid conflicts with other projects.
Amber Roberts, Staff Technical Marketing Manager at Databricks Prior to her time at Databricks, Amber was the ML Growth Lead at Arize AI, where she leaned on her years of experience building models as a data scientist and machine learning engineer. Session 2: Machine Learning withCatBoost This workshop will show how to use CatBoost.
We value super strongly transparency, do open books, have a public roadmap, and contribute to the EFF. You'll work on products like: CRM and Member Management, Web Hosting Infrastructure, Email & SMS Marketing, Events, Classes, and Appointment bookings, and a Member App (PWA). We simplify the entire parking experience.
Importing data from the SageMaker Data Wrangler flow allows you to interact with a sample of the data before scaling the datapreparation flow to the full dataset. This improves time and performance because you don’t need to work with the entirety of the data during preparation.
In the context of ArtificialIntelligence (AI), a modality refers to a specific type or form of data that can be processed and understood by AI models. DataPreparation : The model is provided with a batch of (N) pairs of data points, typically consisting of positive pairs that are related (e.g.,
Forbes reports that global data production increased from 2 zettabytes in 2010 to 44 ZB in 2020, with projections exceeding 180 ZB by 2025 – a staggering 9,000% growth in just 15 years, partly driven by artificialintelligence. However, raw data alone doesn’t equate to actionable insights.
We’re excited to announce Amazon SageMaker Data Wrangler support for Amazon S3 Access Points. In this post, we walk you through importing data from, and exporting data to, an S3 access point in SageMaker Data Wrangler. He wrote a book on AWS FinOps, and enjoys reading and building solutions.
Snowflake is an AWS Partner with multiple AWS accreditations, including AWS competencies in machine learning (ML), retail, and data and analytics. You can import data from multiple data sources, such as Amazon Simple Storage Service (Amazon S3), Amazon Athena , Amazon Redshift , Amazon EMR , and Snowflake.
Data insights are crucial for businesses to enable data-driven decisions, identify trends, and optimize operations. Generative artificialintelligence (AI) has revolutionized this by allowing users to interact with data through natural language queries, providing instant insights and visualizations without needing technical expertise.
The Datamarts capability opens endless possibilities for organizations to achieve their data analytics goals on the Power BI platform. This article is an excerpt from the book Expert Data Modeling with Power BI, Third Edition by Soheil Bakhshi, a completely updated and revised edition of the bestselling guide to Power BI and data modeling.
In the context of ArtificialIntelligence (AI), a modality refers to a specific type or form of data that can be processed and understood by AI models. Primary modalities commonly involved in AI include: Text : This includes any form of written language, such as articles, books, social media posts, and other textual data.
You marked your calendars, you booked your hotel, and you even purchased the airfare. He highlights innovations in data, infrastructure, and artificialintelligence and machine learning that are helping AWS customers achieve their goals faster, mine untapped potential, and create a better future. We’ll see you there!
Only involving necessary people to do case validation or augmentation tasks reduces the risk of document mishandling and human error when dealing with sensitive data. About the Authors Sherry Ding is a senior artificialintelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS).
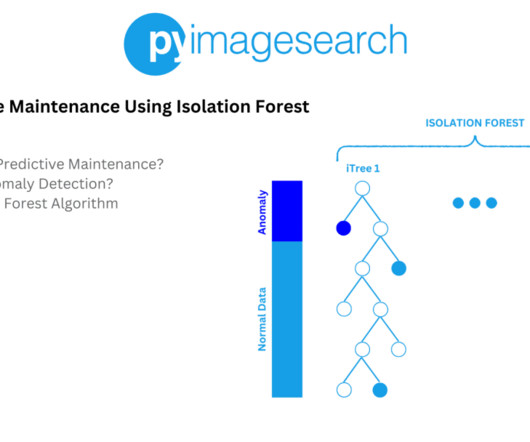
We will start by setting up libraries and datapreparation. Setup and DataPreparation For this purpose, we will use the Pump Sensor Dataset , which contains readings of 52 sensors that capture various parameters (e.g., My mission is to change education and how complex ArtificialIntelligence topics are taught.
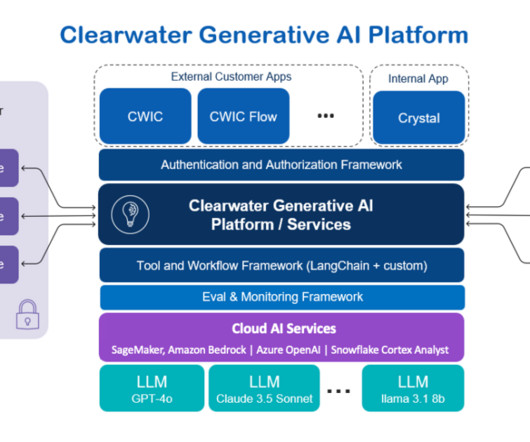
This assistant framework is built upon three pillars: Knowledge awareness Using RAG, CWIC compiles and delivers comprehensive knowledge that is crucial for customers from intricate calculations of book value to period-end reconciliation processes. Pre-trained model teardown Remove the pre-trained model to free up resources.
Youll gain immediate, practical skills in Python, datapreparation, machine learning modeling, and retrieval-augmented generation (RAG), all leading up to AI Agents. Each course features focused, interactive sessions with hands-on notebooks and exercises, along with dedicated office hours. Learn more about the AI Mini Bootcamphere.
Booking Inquiry - Customer asking about making new reservations 2. Reservation Change - Customer wanting to modify existing bookings 3. These requests are ingested into an Amazon Simple Queue Service (Amazon SQS) queue, providing a reliable buffer for incoming data and making sure no requests are lost during peak loads.
Datapreparation In this post, we use several years of Amazon’s Letters to Shareholders as a text corpus to perform QnA on. For more detailed steps to prepare the data, refer to the GitHub repo. Dr. Farooq Sabir is a Senior ArtificialIntelligence and Machine Learning Specialist Solutions Architect at AWS.
These activities cover disparate fields such as basic data processing, analytics, and machine learning (ML). And finally, some activities, such as those involved with the latest advances in artificialintelligence (AI), are simply not practically possible, without hardware acceleration.
Often, to get an NLP application working for production use cases, we end up having to think about datapreparation and cleaning. This is covered with Haystack indexing pipelines , which allows you to design your own datapreparation steps, which ultimately write your documents to the database of your choice.
We will start by setting up libraries and datapreparation. Setup and DataPreparation To start, we will first download the Credit Card Fraud Detection dataset, which contains details (e.g., My mission is to change education and how complex ArtificialIntelligence topics are taught. Download the code!
LLMs are great at having conversations and generating content, but customers want their applications to be able to do even more—like take actions, solve problems, and interact with a range of systems to complete multi-step tasks like booking travel, filing insurance claims, or ordering replacement parts.
Generative artificialintelligence models offer a wealth of capabilities. The latter will map the model’s outputs to final labels and significantly ease the datapreparation process. Book a demo today. They can write poems, recite common knowledge, and extract information from submitted text.
LLMs are already revolutionizing how businesses harness ArtificialIntelligence (AI) in production. Vertex AI provides a suite of tools and services that cater to the entire AI lifecycle, from datapreparation to model deployment and monitoring. Book a demo today. See what Snorkel option is right for you.
LLMs are already revolutionizing how businesses harness ArtificialIntelligence (AI) in production. Vertex AI provides a suite of tools and services that cater to the entire AI lifecycle, from datapreparation to model deployment and monitoring. Book a demo today.
Introduction Large Language Models (LLMs) represent the cutting-edge of artificialintelligence, driving advancements in everything from natural language processing to autonomous agentic systems. They can engage users in natural dialogue, provide customer support, answer FAQs, and assist with booking or shopping decisions.
Key steps encompass: Datapreparation and splitting into training and validation sets. My mission is to change education and how complex ArtificialIntelligence topics are taught. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL! Model initialization.
IBM Watson Supercomputer signifies a leap in artificialintelligence, showcasing capabilities that rapidly transform industries. By harnessing vast amounts of data, Watson can analyze complex queries and provide nuanced insights, revolutionizing problem-solving in fields from healthcare to finance.
Sit back, relax, and enjoy this comprehensive guide to GCP AI Platform your ticket to leveraging cutting-edge artificialintelligence in the cloud. End-to-End ML Operations From datapreparation to model deployment and monitoring, GCP AI Platform supports the entire machine learning lifecycle.
Introduction Machine learning (ML) in 2025 will be continuously evolving because businesses from all industries will utilize artificialintelligence to achieve market superiority. And also here the best book to start your Machine Learning journey in. AWS SageMaker: The Managed ML Powerhouse What is AWS SageMaker?
We will start by setting up libraries and datapreparation. My mission is to change education and how complex ArtificialIntelligence topics are taught. Inside you'll find my hand-picked tutorials, books, courses, and libraries to help you master CV and DL! intrusions or attacks) and “good” normal connections.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























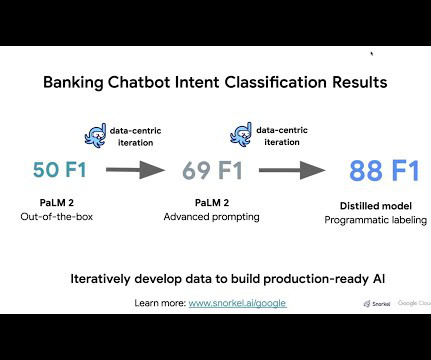
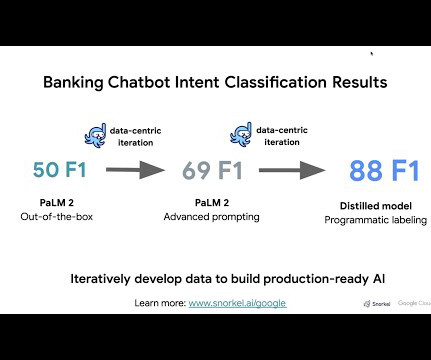
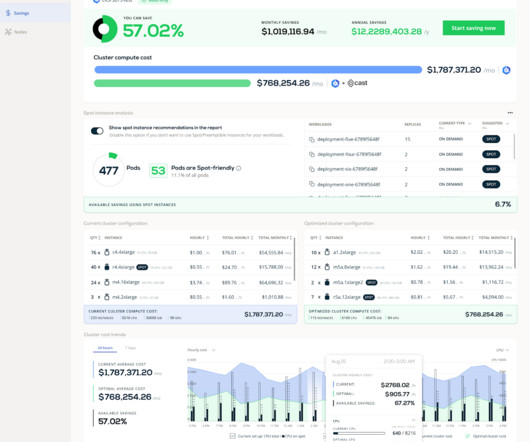











Let's personalize your content