
Amazon SageMaker Feature Store now supports cross-account sharing, discovery, and access
AWS Machine Learning Blog
FEBRUARY 13, 2024
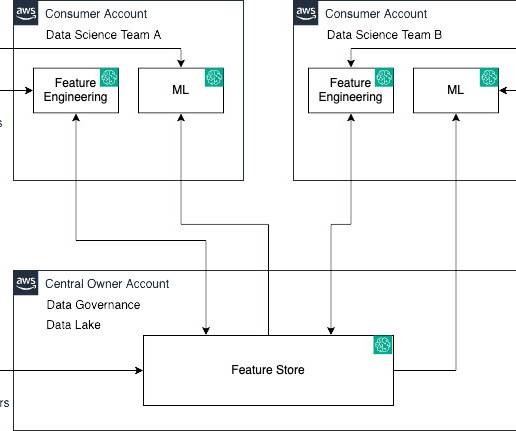
SageMaker Feature Store now makes it effortless to share, discover, and access feature groups across AWS accounts. With this launch, account owners can grant access to select feature groups by other accounts using AWS Resource Access Manager (AWS RAM). Their task is to construct and oversee efficient data pipelines.












Let's personalize your content