
Real-Time Sentiment Analysis with Kafka and PySpark
Towards AI
FEBRUARY 29, 2024
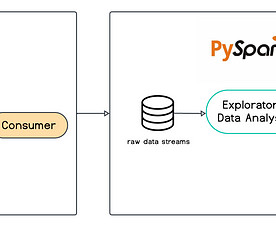
Within this article, we will explore the significance of these pipelines and utilise robust tools such as Apache Kafka and Spark to manage vast streams of data efficiently. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time data pipelines and streaming applications.











Let's personalize your content