This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By Bala Priya C , KDnuggets Contributing Editor & Technical Content Specialist on July 8, 2025 in Data Science Image by Author | Ideogram You know that feeling when you have data scattered across different formats and sources, and you need to make sense of it all? Every ETL pipeline follows the same pattern.
Building the Data Pipeline Before we build our data pipeline, let’s understand the concept of ETL, which stands for Extract, Transform, and Load. ETL is a process where the data pipeline performs the following actions: Extract data from various sources. Transform data into a valid format.
For engineering teams, the underlying technology is open-sourced as Spark Declarative Pipelines , offering transparency and flexibility for advanced users. Lakebridge accelerates the migration of legacy data warehouse workloads to Azure Databricks SQL.
Instead of sweating the syntax, you describe the “ vibe ” of what you want—be it a data pipeline, a web app, or an analytics automation script—and frameworks like Replit, GitHub Copilot, Gemini Code Assist, and others do the heavy lifting. Learn more about LLMs and their applications in this Data Science Dojo guide.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
Dataengineers are the unsung heroes of the data-driven world, laying the essential groundwork that allows organizations to leverage their data for enhanced decision-making and strategic insights. What is a dataengineer?
Over the past few months, we’ve introduced exciting updates to Lakeflow Jobs (formerly known as Databricks Workflows) to improve data orchestration and optimize workflow performance. Refreshed UI for a more focused user experience We’ve redesigned our interface to give Lakeflow Jobs a fresh and modern look.
Data + AI Summit 2025 Announcements At this year’s Data + AI Summit , Databricks announced the General Availability of Lakeflow , the unified approach to dataengineering across ingestion, transformation, and orchestration. Zerobus is currently in Private Preview; reach out to your account team for early access.
In just under 60 minutes, we had a working agent that can transform complex unstructured data usable for Analytics.” — Joseph Roemer, Head of Data & AI, Commercial IT, AstraZeneca “Agent Bricks allowed us to build a cost-effective agent we could trust in production. Agent Bricks is now available in beta.
Both follow the same principles: processing large volumes of data efficiently and ensuring it is clean, consistent, and ready for use. Its key goals are to ensure data quality, consistency, and usability and align data with analytical models or reporting needs. How will you structure data for efficient querying?
Why We Built Databricks One At Databricks, our mission is to democratize data and AI. For years, we’ve focused on helping technical teams—dataengineers, scientists, and analysts—build pipelines, develop advanced models, and deliver insights at scale. and “How can we accelerate growth in the Midwest?”
The new IDE for DataEngineering in Lakeflow Declarative Pipelines We also announced the General Availability of Lakeflow , Databricks’ unified solution for data ingestion, transformation, and orchestration on the Data Intelligence Platform. Preview coming soon. And in the weeks since DAIS, we’ve kept the momentum going.
By subscribing you accept KDnuggets Privacy Policy Leave this field empty if youre human: Get the FREE ebook The Great Big Natural Language Processing Primer and The Complete Collection of Data Science Cheat Sheets along with the leading newsletter on Data Science, Machine Learning, AI & Analytics straight to your inbox.
They sit outside the analytics and AI stack, require manual integration, and lack the flexibility needed for modern development workflows. Deeply integrated with the lakehouse, Lakebase simplifies operational data workflows. As a result, there has been very little innovation in this space for decades.
Skills and Training Familiarity with ethical frameworks like the IEEE’s Ethically Aligned Design, combined with strong analytical and compliance skills, is essential. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with data modeling and ETL processes.
Key launches: Highlights include Lakebase for real-time insights, AI/BI Genie + Deep Research for smarter analytics, and Agent Bricks for GenAI-powered workflows. Developer impact: New tools like Databricks Apps, Lakeflow Designer, and Unity Catalog make it easier for teams of all sizes to build, govern, and scale game data systems.
Scalable Intelligence: The data lakehouse architecture supports scalable, real-time analytics, allowing industrials to monitor and improve key performance indicators, predict maintenance needs, and optimize production processes.
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both data lakes and data warehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
Fortunately, Databricks has compiled these into the Comprehensive Guide to Optimize Databricks, Spark and Delta Lake Workloads , covering everything from data layout and skew to optimizing delta merges and more. Databricks also provides the Big Book of DataEngineering with more tips for performance optimization.
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.
Although we maintain pre-built Amazon QuickSight dashboards for commonly tracked metrics, business users frequently require support for long-tail analytics—the ability to conduct deep dives into specific problems, anomalies, or regional variations not covered by standard reports.
Scope of DataOps DataOps encompasses several core areas to ensure efficient data management: Data development: This involves designing and building data systems that meet organizational needs. Data transformation: The process of converting raw data into useful formats that serve analytical and operational purposes.
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 5 Ways to Transition Into AI from a Non-Tech Background You have a non-tech background?
To address these challenges, AWS has expanded Amazon SageMaker with a comprehensive set of data, analytics, and generative AI capabilities. There are three personas: admin, dataengineer, and user, which can be a data scientist or an ML engineer.
Data Visualization & Analytics Explore creative and technical approaches to visualizing complex datasets, designing dashboards, and communicating insights effectively. Ideal for anyone focused on translating data into impactful visuals and stories.
This blog post explores effective strategies for gathering requirements in your data project. Whether you are a data analyst , project manager, or dataengineer, these approaches will help you clarify needs, engage stakeholders, and ensure requirements gathering techniques to create a roadmap for success.
She has experience across analytics, big data, ETL, cloud operations, and cloud infrastructure management. DataEngineer at Amazon Ads. He builds and manages data-driven solutions for recommendation systems, working together with a diverse and talented team of scientists, engineers, and product managers.
Amazon Web Services (AWS) returns as a Legend Sponsor at Data + AI Summit 2025 , the premier global event for data, analytics, and AI. Taking place in San Francisco and virtually from June 9-12 , this year’s summit will bring together 20,000+ data leaders and practitioners to explore the impact and future of data and AI.
Simple business questions can become multi-day ordeals, with analytics teams drowning in routine requests instead of focusing on strategic initiatives. Nicolas Alvarez is a DataEngineer within the Amazon Worldwide Returns and ReCommerce Data Services team, focusing on building and optimizing recommerce data systems.
The field of data science is now one of the most preferred and lucrative career options available in the area of data because of the increasing dependence on data for decision-making in businesses, which makes the demand for data science hires peak. Their insights must be in line with real-world goals.
Strengthening Defenses with Advanced Fraud Analytics Protecting the network, customers and the business from fraud, compliance risks and cyber threats is paramount. Our joint fraud analytics solutions leverage the power of machine learning on the Databricks Data Intelligence Platform.
This following diagram illustrates the enhanced data extract, transform, and load (ETL) pipeline interaction with Amazon Bedrock. To achieve the desired accuracy in KPI calculations, the data pipeline was refined to achieve consistent and precise performance, which leads to meaningful insights.
Thats why we use advanced technology and dataanalytics to streamline every step of the homeownership experience, from application to closing. Data refinement: Raw data is refined into consumable layers (raw, processed, conformed, and analytical) using a combination of AWS Glue extract, transform, and load (ETL) jobs and EMR jobs.
Previously, he was a Data & Machine Learning Engineer at AWS, where he worked closely with customers to develop enterprise-scale data infrastructure, including data lakes, analytics dashboards, and ETL pipelines. He specializes in designing, building, and optimizing large-scale data solutions.
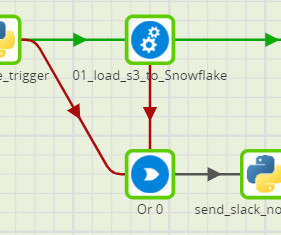
Modern low-code/no-code ETL tools allow dataengineers and analysts to build pipelines seamlessly using a drag-and-drop and configure approach with minimal coding. One such option is the availability of Python Components in Matillion ETL, which allows us to run Python code inside the Matillion instance.
I worked extensively with ETL processes, PostgreSQL, and later, enterprise-scale data systems. Ive always had a logical, data-driven mindset, constantly digging deeper into metrics and questioning assumptions. When I discovered the field of dataanalytics, it felt like a perfect fit.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















































Let's personalize your content