This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Its key goals are to ensure data quality, consistency, and usability and align data with analytical models or reporting needs. Its key goals are to store data in a format that supports fast querying and scalability and to enable real-time or near-real-time access for decision-making. How often should dashboards update?
Blog Top Posts About Topics AI Career Advice Computer Vision DataEngineeringData Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Go vs. Python for Modern Data Workflows: Need Help Deciding?
TL;DR – What you’ll learn Why lakehouses combine the flexibility of datalakes with the governance and performance of warehouses to cut friction in AI adoption. How modern file formats (Iceberg, Delta Lake) and open object storage enable real-time analytics, schema management, and engine interoperability.
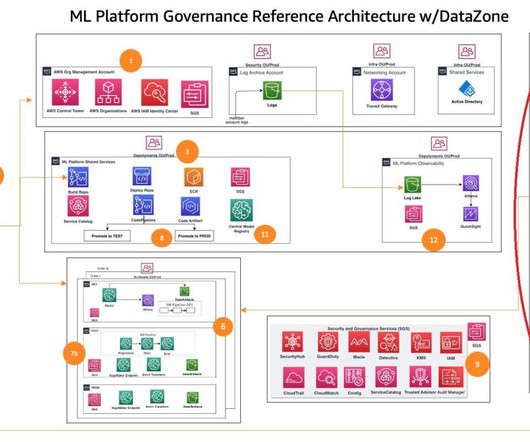
It enables different business units within an organization to create, share, and govern their own data assets, promoting self-service analytics and reducing the time required to convert data experiments into production-ready applications. We discuss this in more detail later in this post.
They sit outside the analytics and AI stack, require manual integration, and lack the flexibility needed for modern development workflows. At zero, the cost of the lakebase is just the cost of storing the data on cheap datalakes. As a result, there has been very little innovation in this space for decades.
Data Lakehouse has emerged as a significant innovation in data management architecture, bridging the advantages of both datalakes and data warehouses. By enabling organizations to efficiently store various data types and perform analytics, it addresses many challenges faced in traditional data ecosystems.
Scalable Intelligence: The data lakehouse architecture supports scalable, real-time analytics, allowing industrials to monitor and improve key performance indicators, predict maintenance needs, and optimize production processes.
Although we maintain pre-built Amazon QuickSight dashboards for commonly tracked metrics, business users frequently require support for long-tail analytics—the ability to conduct deep dives into specific problems, anomalies, or regional variations not covered by standard reports.
Simple business questions can become multi-day ordeals, with analytics teams drowning in routine requests instead of focusing on strategic initiatives. Nicolas Alvarez is a DataEngineer within the Amazon Worldwide Returns and ReCommerce Data Services team, focusing on building and optimizing recommerce data systems.
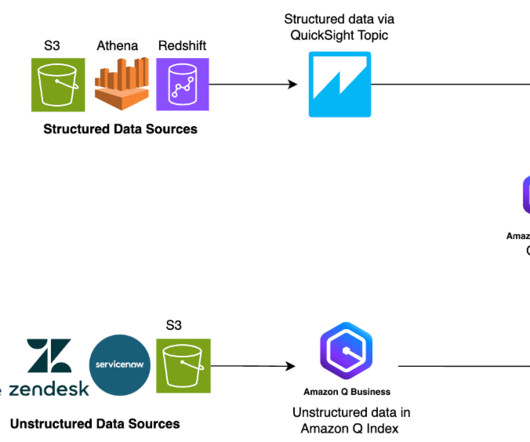
Beyond foundational use cases like technical troubleshooting, email drafting, and content refinement, we aimed to equip teams with a natural language interface to query enterprise data across domains. These approaches provide precise, context-aware responses while maintaining data governance.
At the heart of this transformation is the OMRON Data & Analytics Platform (ODAP), an innovative initiative designed to revolutionize how the company harnesses its data assets. The robust security features provided by Amazon S3, including encryption and durability, were used to provide data protection.
The most used open table formats currently are Apache Iceberg, Delta Lake, and Apache Hudi. These systems are built on open standards and offer immense analytical and transactional processing flexibility. Adopting an Open Table Format architecture is becoming indispensable for modern data systems. Why are They Essential?
To achieve the desired accuracy in KPI calculations, the data pipeline was refined to achieve consistent and precise performance, which leads to meaningful insights. At this point, it became possible for the calculator agent to forego the Pandas or Spark data processing implementation.
Among these, four primary use cases have emerged as especially prominent: intelligent process automation, anomaly detection, analytics, and operational assistance. Different types of data typically require different tools to access them. years of experience in DataEngineering, ML and AI.
He specializes in large language models, cloud infrastructure, and scalable data systems, focusing on building intelligent solutions that enhance automation and data accessibility across Amazons operations. Chaithanya Maisagoni is a Senior Software Development Engineer (AI/ML) in Amazons Worldwide Returns and ReCommerce organization.
PlotlyInteractive Data Visualization Plotly is a leader in interactive data visualization tools, offering open-source graphing libraries in Python, R, JavaScript, and more. Their solutions, including Dash, make it easier for developers and data scientists to build analytical web applications with minimalcoding.
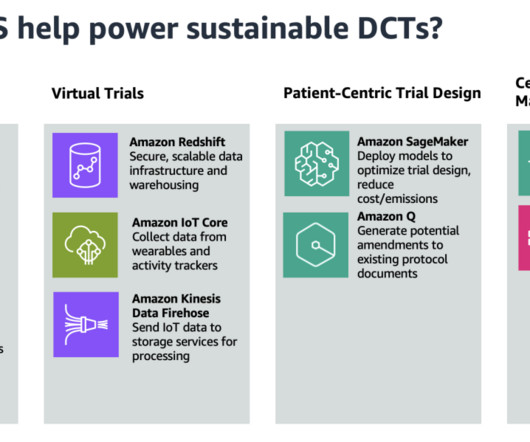
Instead, a core component of decentralized clinical trials is a secure, scalable data infrastructure with strong dataanalytics capabilities. Amazon Redshift is a fully managed cloud data warehouse that trial scientists can use to perform analytics.
Thats why we use advanced technology and dataanalytics to streamline every step of the homeownership experience, from application to closing. This also led to a backlog of data that needed to be ingested. Analyticdata is stored in Amazon Redshift. Dataengineering development is done using AWS Glue Studio.
Quotes Data governance is going to play a large role in what data can go into an LLM. VP of Analytics, Finance Industry It will be increasingly important for organizations to understand how LLMs are trained -- whether on the company's own data or paired with others. No problem!
In this article, we will explore the evolution of Iceberg, its key features like ACID transactions, partition evolution, and time travel, and how it integrates with modern datalakes. appeared first on Analytics Vidhya. Well also dive into […] The post How to Use Apache Iceberg Tables?
EvolvabilityIts Mostly About Data Contracts Editors note: Elliott Cordo is a speaker for ODSC East this May 1315! Be sure to check out his talk, Enabling Evolutionary Architecture in DataEngineering , there to learn about data contracts and plentymore.
Big dataengineers are essential in today’s data-driven landscape, transforming vast amounts of information into valuable insights. As businesses increasingly depend on big data to tailor their strategies and enhance decision-making, the role of these engineers becomes more crucial.
Image Source: GitHub Table of Contents What is DataEngineering? Components of DataEngineering Object Storage Object Storage MinIO Install Object Storage MinIO DataLake with Buckets Demo DataLake Management Conclusion References What is DataEngineering?
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a centralized repository for storing, processing, and securing massive amounts of structured, semi-structured, and unstructured data. It can store data in its native format and process any type of data, regardless of size.
Introduction Today, DataLake is most commonly used to describe an ecosystem of IT tools and processes (infrastructure as a service, software as a service, etc.) that work together to make processing and storing large volumes of data easy. An ecosystem consists of […].
This article will discuss some of the features and applications of data warehouses, data marts, and data […]. The post Data Warehouses, Data Marts and DataLakes appeared first on Analytics Vidhya.
Data collection is critical for businesses to make informed decisions, understand customers’ […]. The post DataLake or Data Warehouse- Which is Better? appeared first on Analytics Vidhya. We can use it to represent facts, figures, and other information that we can use to make decisions.
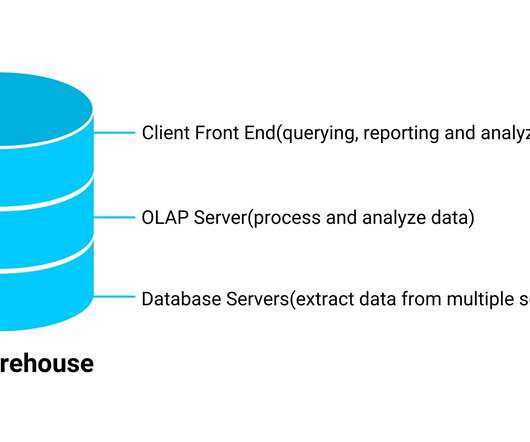
Overview Understand the meaning of datalake and data warehouse We will see what are the key differences between Data Warehouse and DataLake. The post What are the differences between DataLake and Data Warehouse? appeared first on Analytics Vidhya.
Introduction We are all pretty much familiar with the common modern cloud data warehouse model, which essentially provides a platform comprising a datalake (based on a cloud storage account such as Azure DataLake Storage Gen2) AND a data warehouse compute engine […].
ArticleVideo Book This article was published as a part of the Data Science Blogathon. Introduction DataLake architecture for different use cases – Elegant. The post A Guide to Build your DataLake in AWS appeared first on Analytics Vidhya.
This article was published as a part of the Data Science Blogathon. Introduction A datalake is a central data repository that allows us to store all of our structured and unstructured data on a large scale. The post A Detailed Introduction on DataLakes and Delta Lakes appeared first on Analytics Vidhya.
Now, businesses are looking for different types of data storage to store and manage their data effectively. Organizations can collect millions of data, but if they’re lacking in storing that data, those efforts […] The post A Comprehensive Guide to DataLake vs. Data Warehouse appeared first on Analytics Vidhya.
Never-ending data requests – because no one can find (or trust) the right query, engineers and analytics teams still get pinged for “one more pull.” You’ll own and work with everything from distributed queues and datalakes to prompt evaluation and agentic orchestration. Work style: Hybrid in NYC/CT.
Introduction Delta Lake is an open-source storage layer that brings datalakes to the world of Apache Spark. Delta Lakes provides an ACID transaction–compliant and cloud–native platform on top of cloud object stores such as Amazon S3, Microsoft Azure Storage, and Google Cloud Storage.
Introduction A datalake is a centralized and scalable repository storing structured and unstructured data. The need for a datalake arises from the growing volume, variety, and velocity of data companies need to manage and analyze.
Introduction Most of you would know the different approaches for building a data and analytics platform. You would have already worked on systems that used traditional warehouses or Hadoop-based datalakes. The post Warehouse, Lake or a Lakehouse – What’s Right for you? Selecting one among […].
Enterprises have slowly started adopting Lakehouses for their data ecosystems as they offer cost efficiencies of datalakes and the performance of warehouses. […]. The post Delta Lake in Action – Quick Hands-on Tutorial for Beginners appeared first on Analytics Vidhya.
Dataengineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Essential dataengineering tools for 2023 Top 10 dataengineering tools to watch out for in 2023 1.
Delta Lake allows businesses to access and break new data down in real time. Delta Lake is an open-source warehouse layer designed to run on top of datalakes analogous to […] The post A Comprehensive Guide on Delta Lake appeared first on Analytics Vidhya.
Continuous Integration and Continuous Delivery (CI/CD) for Data Pipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable data pipelines is paramount in data science and dataengineering. It offers full BI-Stack Automation, from source to data warehouse through to frontend.
A recent article on Analytics Insight explores the critical aspect of dataengineering for IoT applications. Understanding the intricacies of dataengineering empowers data scientists to design robust IoT solutions, harness data effectively, and drive innovation in the ever-expanding landscape of connected devices.
Microsoft Fabric aims to reduce unnecessary data replication, centralize storage, and create a unified environment with its unique data fabric method. Microsoft Fabric is a cutting-edge analytics platform that helps data experts and companies work together on data projects. What is Microsoft Fabric?
Microsoft has made good on its promise to deliver a simplified and more efficient Microsoft Fabric price model for its end-to-end platform designed for analytics and data workloads. Microsoft’s unified pricing model for the Fabric suite marks a significant advancement in the analytics and data market.
Dataengineers play a crucial role in managing and processing big data. They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. What is dataengineering?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content