
What is Alteryx certification: A comprehensive guide
Pickl AI
FEBRUARY 4, 2024
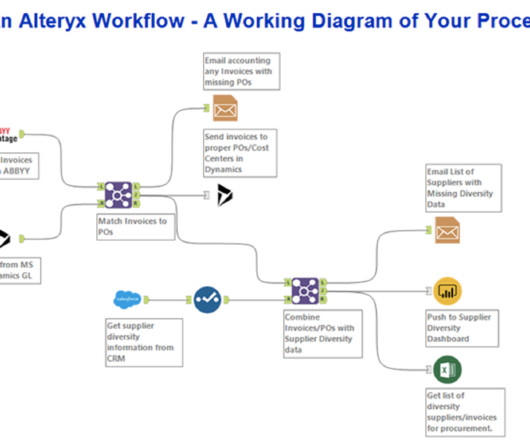
Alteryx’s Capabilities Data Blending: Effortlessly combine data from multiple sources. Predictive Analytics: Leverage machine learning algorithms for accurate predictions. This makes Alteryx an indispensable tool for businesses aiming to glean insights and steer their decisions based on robust data.










Let's personalize your content