

Fast and cost-effective LLaMA 2 fine-tuning with AWS Trainium
AWS Machine Learning Blog
OCTOBER 5, 2023
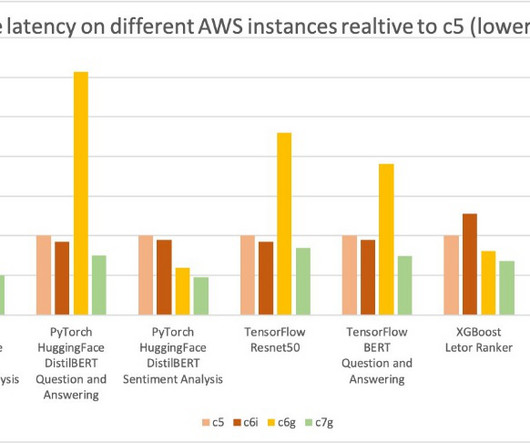
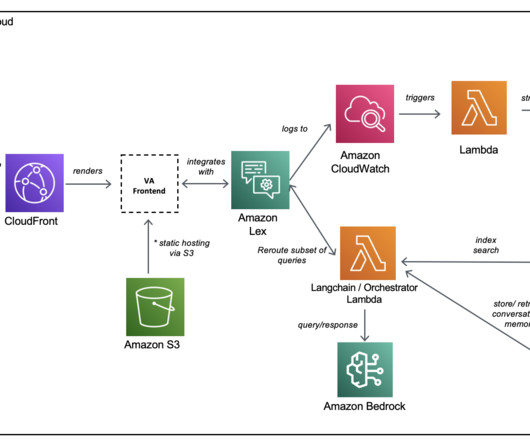
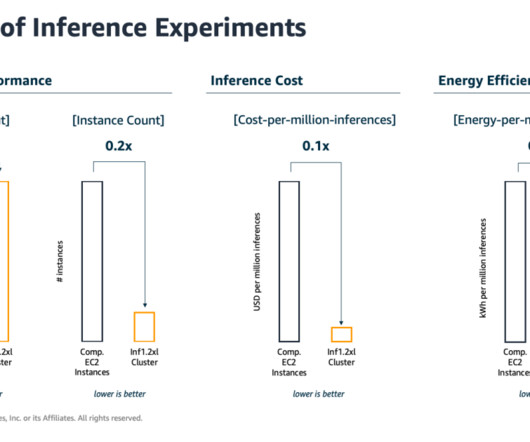
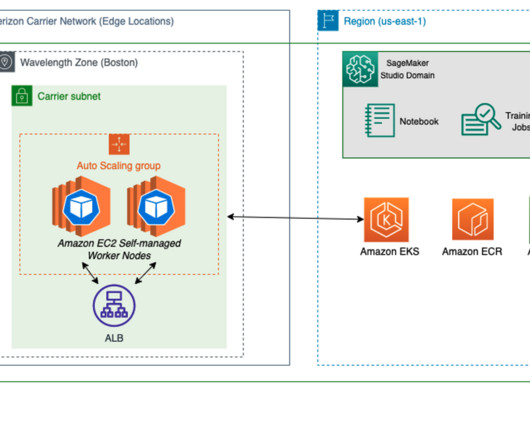
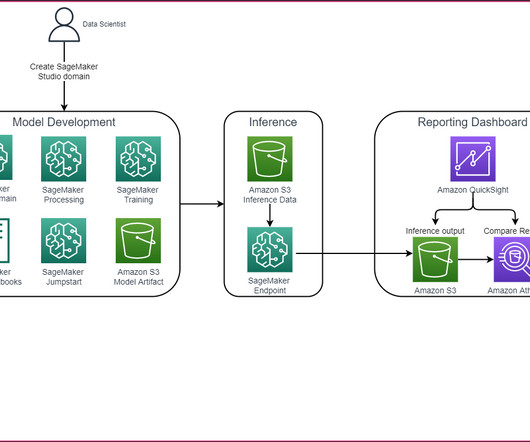
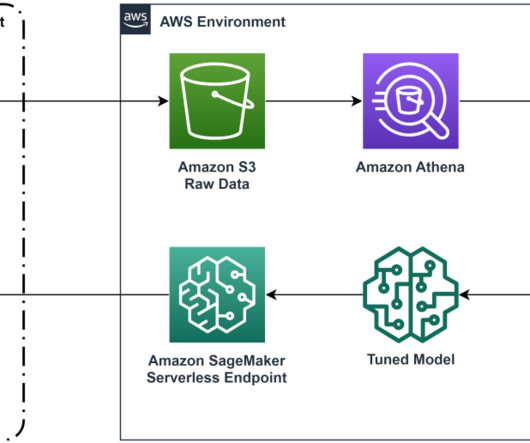
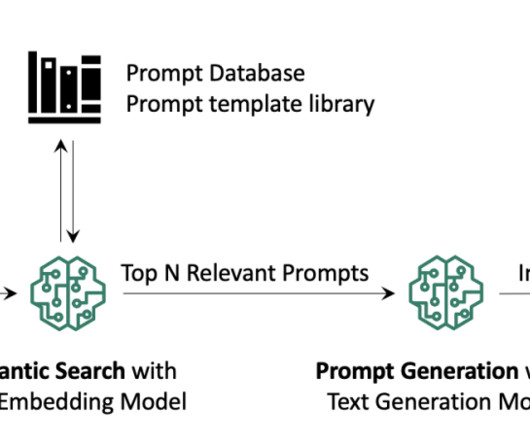
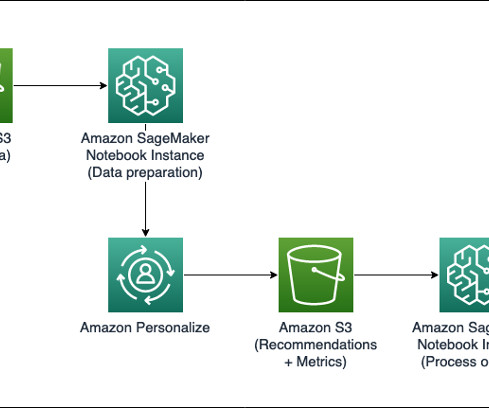
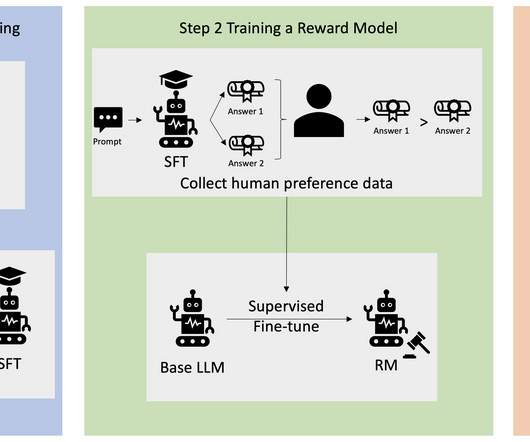
In this post, we walk through how to fine-tune Llama 2 on AWS Trainium , a purpose-built accelerator for LLM training, to reduce training times and costs. We review the fine-tuning scripts provided by the AWS Neuron SDK (using NeMo Megatron-LM), the various configurations we used, and the throughput results we saw.


























Let's personalize your content