
Text Classification in NLP using Cross Validation and BERT
Mlearning.ai
FEBRUARY 15, 2023
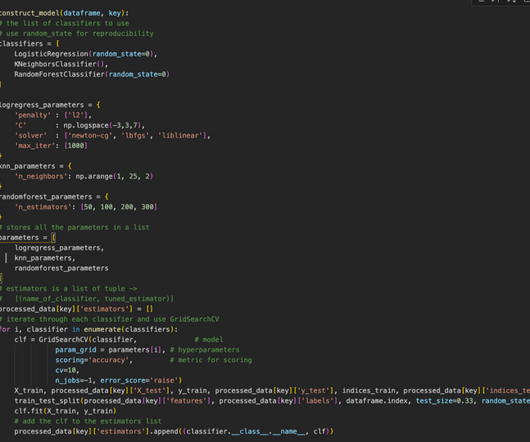
Figure 4 Data Cleaning Conventional algorithms are often biased towards the dominant class, ignoring the data distribution. For some applications, such as fraud detection or cancer prediction, we may need to configure our model carefully or artificially balance the dataset, such as by undersampling or oversampling each class.









Let's personalize your content