

How to use foundation models and trusted governance to manage AI workflow risk
IBM Journey to AI blog
OCTOBER 16, 2023
Artificial intelligence (AI) adoption is still in its early stages. As more businesses use AI systems and the technology continues to mature and change, improper use could expose a company to significant financial, operational, regulatory and reputational risks. ” Are foundation models trustworthy?

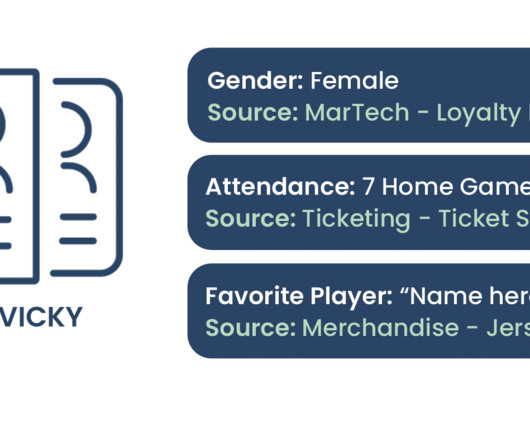












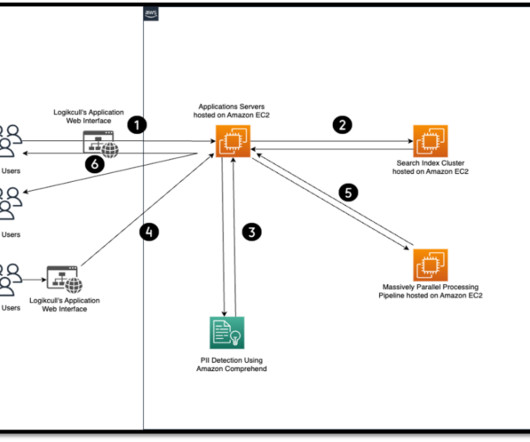


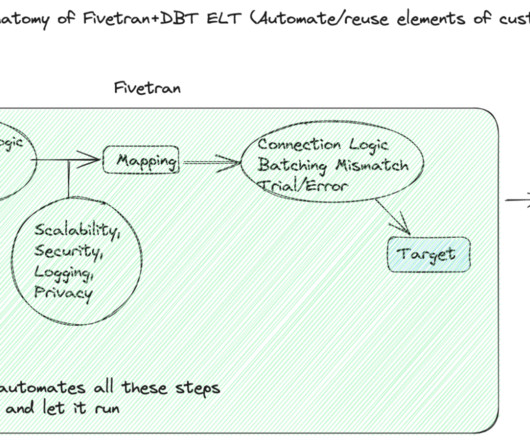










Let's personalize your content