

ALBERT Model for Self-Supervised Learning
Analytics Vidhya
OCTOBER 19, 2022
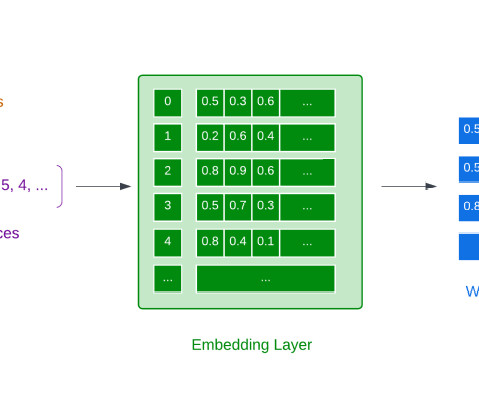
Source: Canva Introduction In 2018, Google AI researchers came up with BERT, which revolutionized the NLP domain. Later in 2019, the researchers proposed the ALBERT (“A Lite BERT”) model for self-supervised learning of language representations, which shares the same architectural backbone as BERT. The key […].

















Let's personalize your content