
Oracle Shared Pool Internals: Allocated Chunk Status Indicators in Heap Dumps
Hacker News
APRIL 23, 2024
Linux, Oracle, SQL performance tuning and troubleshooting - consulting & training.

Hacker News
APRIL 23, 2024
Linux, Oracle, SQL performance tuning and troubleshooting - consulting & training.
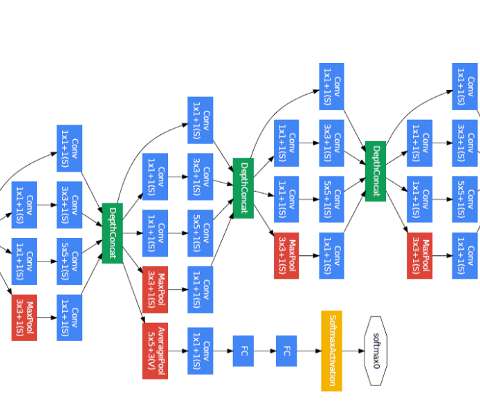
Analytics Vidhya
JULY 22, 2022
BigQuery was first launched as a service in 2010, with general availability in November 2011. This article was published as a part of the Data Science Blogathon Introduction Google’s BigQuery is an enterprise-grade cloud-native data warehouse.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.
KDnuggets
JANUARY 7, 2020
An estimated 8,650% growth of the volume of Data to 175 zetabytes from 2010 to 2025 has created an enormous need for Data Engineers to build an organization's big data platform to be fast, efficient and scalable.

AWS Machine Learning Blog
DECEMBER 6, 2023
Overview of RAG RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and natural language processing (NLP) tasks since 2010. But how can we implement and integrate this approach to an LLM-based conversational AI?

Data Science Dojo
OCTOBER 10, 2023
A Glimpse into the future : Want to be like a scientist who predicted the rise of machine learning back in 2010? 360 Topics: The event will delve into a wide range of topics including SQL Server, Visual Studio, Artificial Intelligence, DevOps,NET, and more, providing insights into Microsoft Tech and IT. Link to event -> Live!

Towards AI
NOVEMBER 9, 2023
Created by Author with Dall-E2 In the previous article, we learned how to set up a prompt able to generate SQL commands from the user requests. Now, we will see how to use Azure OpenAI Studio to create an inference endpoint that we can call to generate SQL commands. Jusct clicking on the Deployment name we can start working.

Data Science Dojo
MAY 3, 2023
Most Data Science enthusiasts know how to write queries and fetch data from SQL but find they may find the concept of indexing to be intimidating. Using the “Top Spotify songs from 2010-2019” dataset on Kaggle ( [link] ), we read it into a Python – Pandas Data Frame.

Expert insights. Personalized for you.







Let's personalize your content