
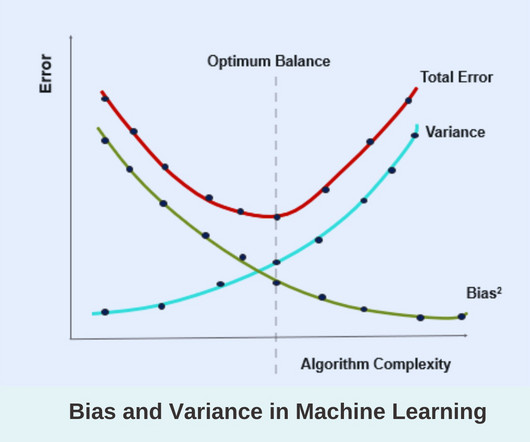
Bias and Variance in Machine Learning
Pickl AI
JULY 26, 2023
Gender Bias in Natural Language Processing (NLP) NLP models can develop biases based on the data they are trained on. K-Nearest Neighbors with Small k I n the k-nearest neighbours algorithm, choosing a small value of k can lead to high variance. to enhance your skills.









Let's personalize your content