
2024 Tech breakdown: Understanding Data Science vs ML vs AI
Pickl AI
JANUARY 29, 2024
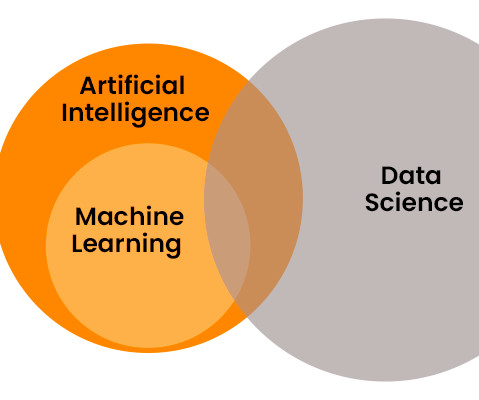
Key Components In Data Science, key components include data cleaning, Exploratory Data Analysis, and model building using statistical techniques. ML focuses on algorithms like decision trees, neural networks, and support vector machines for pattern recognition. billion by 2029.












Let's personalize your content