

Comparing Tools For Data Processing Pipelines
The MLOps Blog
MARCH 15, 2023
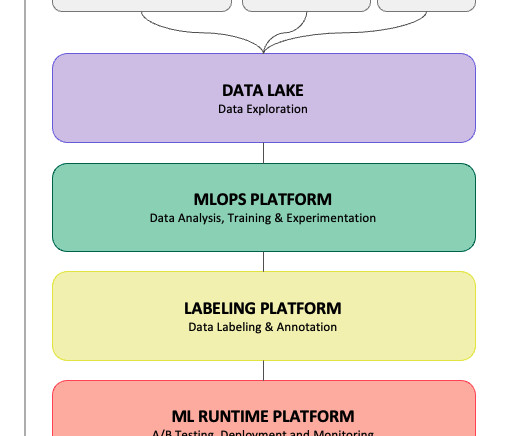
In this post, you will learn about the 10 best data pipeline tools, their pros, cons, and pricing. A typical data pipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.















Let's personalize your content