


Fully Explained Softmax Regression for Multi-Class Label with Python
Towards AI
OCTOBER 15, 2023
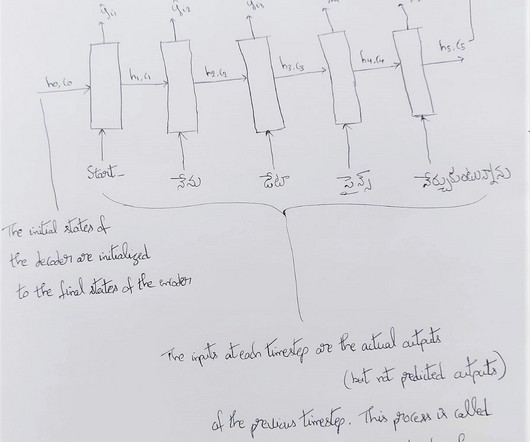
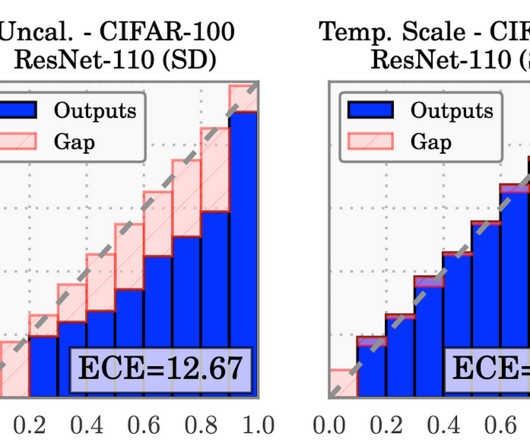
Some of the learners may think that we are doing a classification problem, but we are using… Read the full blog for free on Medium. For logistic regression, we can say, it is a form of soft-max regression. Join thousands of data leaders on the AI newsletter. From research to projects and ideas.





























Let's personalize your content