

Comprehensive Guide: Top Computer Vision Resources All in One Blog
Mlearning.ai
JANUARY 27, 2023
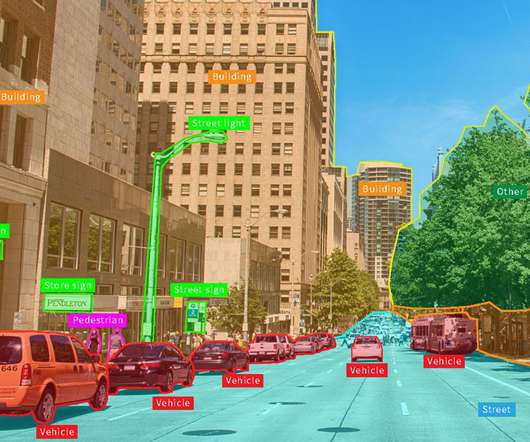
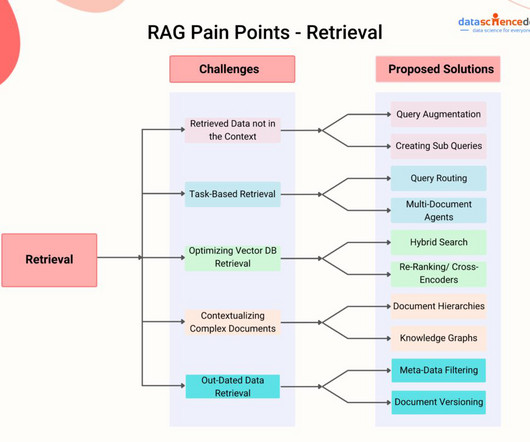
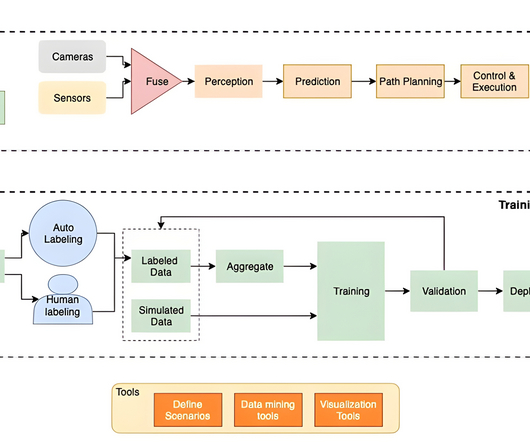
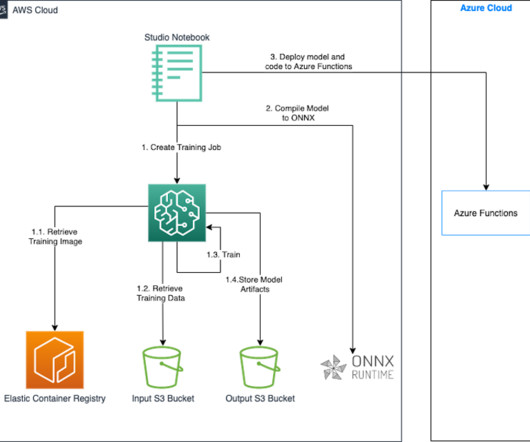
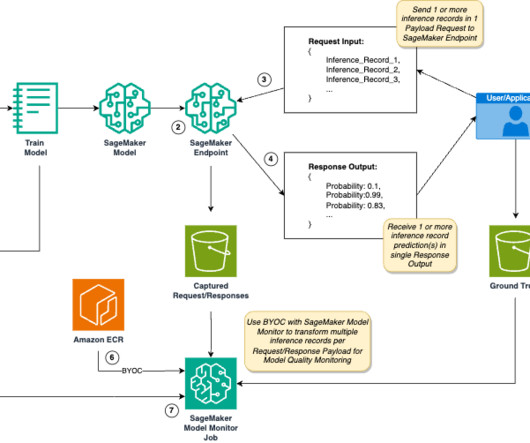
Save this blog for comprehensive resources for computer vision Source: appen Working in computer vision and deep learning is fantastic because, after every few months, someone comes up with something crazy that completely changes your perspective on what is feasible. A dataset is a group of samples (in this case, photos or videos).






















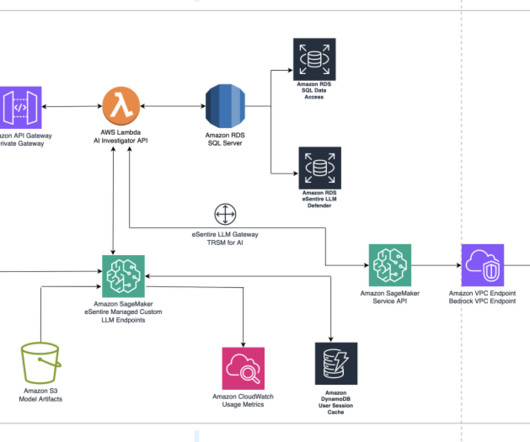



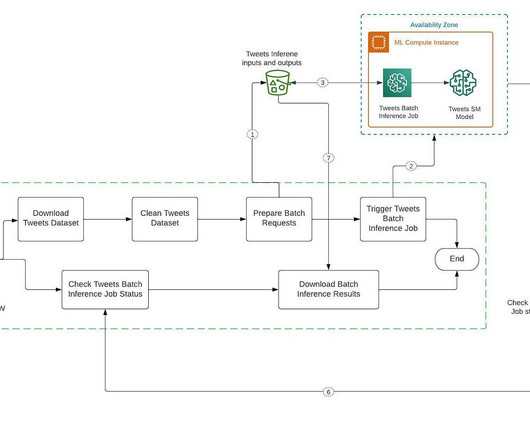






Let's personalize your content