

Accelerating AI/ML development at BMW Group with Amazon SageMaker Studio
NOVEMBER 24, 2023
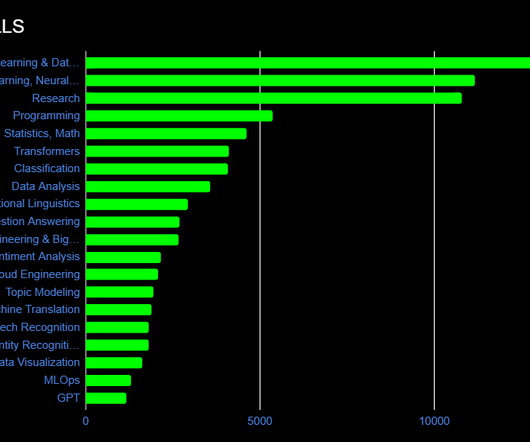
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. Data scientists and ML engineers require capable tooling and sufficient compute for their work. Data scientists and ML engineers require capable tooling and sufficient compute for their work.






































Let's personalize your content