This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s combine these suggestions to improve upon our original prompt: Human: Your job is to act as an expert on ETL pipelines. Specifically, your job is to create a JSON representation of an ETL pipeline which will solve the user request provided to you.
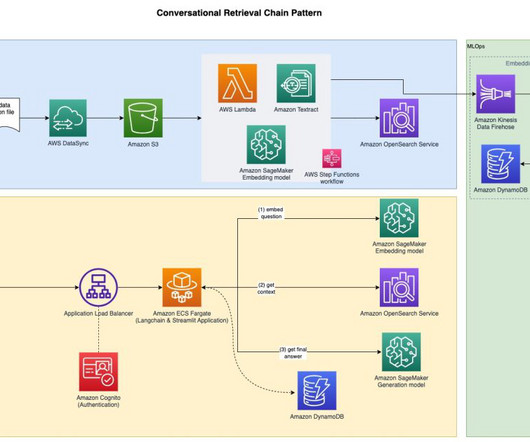
The embeddings are captured in Amazon Simple Storage Service (Amazon S3) via Amazon Kinesis Data Firehose , and we run a combination of AWS Glue extract, transform, and load (ETL) jobs and Jupyter notebooks to perform the embedding analysis. Set the parameters for the ETL job as follows and run the job: Set --job_type to BASELINE.
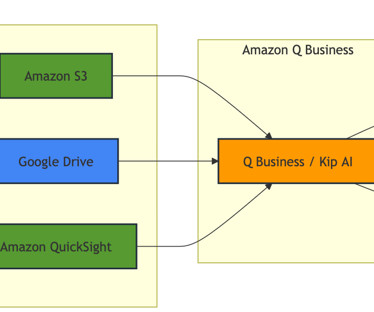
We use multiple data sources, including Amazon S3 for our storage needs, Amazon QuickSight for our business intelligence requirements, and Google Drive for team collaboration. About the authors Evan Miller , Global Head of Product and DataScience, is a strategic product leader who joined Kepler 2013.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








Let's personalize your content