

Feature Platforms?—?A New Paradigm in Machine Learning Operations (MLOps)
IBM Data Science in Practice
MARCH 8, 2023
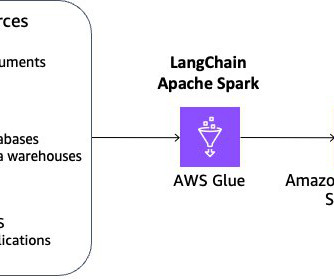
Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Tools like Git and Jenkins are not suited for managing data. This is where a feature platform comes in handy. Spark, Flink, etc.)







Let's personalize your content