This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 8 Ways to Scale your Data Science Workloads From in-spreadsheet machine learning to terabyte sized DataFrames, learn how to stop fighting your tools and focus on solving problems.
Evaluating the performance of Large Language Models (LLMs) is an important and necessary step in refining it. LLMs are used in solving many different problems ranging from text classification and information extraction. Choosing the correct metrics to measure the performance of an LLM can greatly increase the effectiveness of the model. In this blog, we will explore one such crucial metric the F1 score.
Summary: Python exception handling is essential for managing errors during program execution. By using try-except blocks, developers can catch exceptions and respond appropriately, preventing crashes and enhancing user experience. This guide covers the basics, including raising custom exceptions and employing best practices for effective error management.
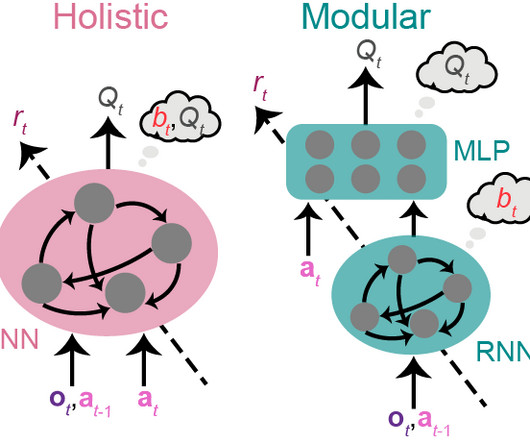
TL;DR: The brain may have evolved a modular architecture for daily tasks, with circuits featuring functionally specialized modules that match the task structure. We hypothesize that this architecture enables better learning and generalization than architectures with less specialized modules. To test this, we trained reinforcement learning agents with various neural architectures on a naturalistic navigation task.
Speaker: Jason Chester, Director, Product Management
In today’s manufacturing landscape, staying competitive means moving beyond reactive quality checks and toward real-time, data-driven process control. But what does true manufacturing process optimization look like—and why is it more urgent now than ever? Join Jason Chester in this new, thought-provoking session on how modern manufacturers are rethinking quality operations from the ground up.
Phishing emails, those deceptive messages designed to steal sensitive information, remain a significant cybersecurity threat. As attackers devise increasingly sophisticated tactics, traditional detection methods often fall short. Researchers from the University of Auckland, have introduced a novel approach to combat this issue. Their paper, titled “ MultiPhishGuard: An LLM-based Multi-Agent System for Phishing Email Detection ,” authored by Yinuo Xue, Eric Spero, Yun Sing Koh, and Gi
Home Table of Contents Anomaly Detection: How to Find Outliers Using the Grubbs Test What Is an Outlier? How to Find Outliers with Grubbs Test Formulating the Hypotheses Null Hypothesis Alternative Hypothesis Calculate the Test Statistic Determining the Critical Value with t-Distribution Key Characteristics of the t-Distribution Performing the Grubbs Test Left-Tailed Grubbs Test Right-Tailed Grubbs Test Two-Tailed Grubbs Test Summary Citation Information Anomaly Detection: How to Find Outliers U
Large language model embeddings, or LLM embeddings, are a powerful approach to capturing semantically rich information in text and utilizing it to leverage other machine learning models — like those trained using Scikit-learn — in tasks that require deep contextual understanding of text, such as intent recognition or sentiment analysis.
Large language model embeddings, or LLM embeddings, are a powerful approach to capturing semantically rich information in text and utilizing it to leverage other machine learning models — like those trained using Scikit-learn — in tasks that require deep contextual understanding of text, such as intent recognition or sentiment analysis.
Skip to main content Login Why Databricks Discover For Executives For Startups Lakehouse Architecture Mosaic Research Customers Customer Stories Partners Cloud Providers Databricks on AWS, Azure, GCP, and SAP Consulting & System Integrators Experts to build, deploy and migrate to Databricks Technology Partners Connect your existing tools to your Lakehouse C&SI Partner Program Build, deploy or migrate to the Lakehouse Data Partners Access the ecosystem of data consumers Partner Solutions
Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models.
Today's AI systems have human-designed, fixed architectures and cannot autonomously and continuously improve themselves. The advance of AI could itself be automated. If done safely, that would accelerate AI development and allow us to reap its benefits much sooner. Meta-learning can automate the discovery of novel algorithms, but is limited by first-order improvements and the human design of a suitable search space.
The world’s leading publication for data science, AI, and ML professionals. Sign in Sign out Contributor Portal Latest Editor’s Picks Deep Dives Contribute Newsletter Toggle Mobile Navigation LinkedIn X Toggle Search Search Data Science How I Automated My Machine Learning Workflow with Just 10 Lines of Python Use LazyPredict and PyCaret to skip the grunt work and jump straight to performance.
ETL and ELT are some of the most common data engineering use cases, but can come with challenges like scaling, connectivity to other systems, and dynamically adapting to changing data sources. Airflow is specifically designed for moving and transforming data in ETL/ELT pipelines, and new features in Airflow 3.0 like assets, backfills, and event-driven scheduling make orchestrating ETL/ELT pipelines easier than ever!
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter How to Combine Streamlit, Pandas, and Plotly for Interactive Data Apps With just two Python files and a handful of methods, you can build a complete dashboard that rivals expensive business intelligence tools.
Generative AI research is rapidly transforming the landscape of artificial intelligence, driving innovation in large language models, AI agents, and multimodal systems. Staying current with the latest breakthroughs is essential for data scientists, AI engineers, and researchers who want to leverage the full potential of generative AI. In this comprehensive roundup, we highlight this week’s top 4 research papers in generative AI research, each representing a significant leap in technical sophist
Summary: Accuracy in Machine Learning measures correct predictions but can be deceptive, particularly with imbalanced or multilabel data. The blog explains the limitations of using accuracy alone. It introduces alternative metrics like precision, recall, F1-score, confusion matrices, ROC curves, and Hamming metrics to evaluate models, ensuring improved insights comprehensively.
The second week of the Agentic AI Summit built upon week 1 by diving deeper into the engineering realities of agentic AI — from protocol-level orchestration to agent deployment inside enterprise environments and even developer IDEs. Leaders from Monte Carlo, TrueFoundry, LlamaIndex, TripAdvisor, and more shared how they’re moving from prototypes to production, surfacing the tools, patterns, and challenges they’ve encountered along the way.
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.
The latest guest on our series is Madhura Raut, Lead Data Scientist and the seed engineer for global leader tech platform for human capital management. As an internationally recognized expert in artificial intelligence and machine learning, Madhura has made extraordinary contributions to the field through her pioneering work in labor demand forecasting systems and her role in advancing the state-of-the-art in time-series prediction methodologies.
( Dylan Foster and Alex Lamb both helped in creating this.) In thinking about what are good research problems, its sometimes helpful to switch from what is understood to what is clearly possible. This encourages us to think beyond simply improving the existing system. For example, we have seen instances throughout the history of machine learning where researchers have argued for fixing an architecture and using it for short-term success, ignoring potential for long-term disruption.
MLOps, or machine learning operations, is all about managing the end-to-end process of building, training, deploying, and maintaining machine learning models.
TL;DR Multimodal AI at scale demands more than fast hardware—it requires a fundamentally different architecture. Vespa AI brings compute to the data, enabling real-time performance across text, images, and video. Companies like Spotify, Perplexity, and Vinted rely on Vespa to power search, recommendations, and RAG at global scale. Tensor-based retrieval and hybrid ranking strategies make Vespa uniquely capable of supporting complex multimodal use cases.
Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Vision Language Models (VLMs) enable visual understanding alongside textual inputs. They are typically built by passing visual tokens from a pretrained vision encoder to a pretrained Large Language Model (LLM) through a projection layer. By leveraging the rich visual representations of the vision encoder and the world knowledge and reasoning capabilities of the LLM, VLMs can be useful for a wide range of applications, including accessibility assistants, UI navigation, robotics, and gaming.
Jump to Content Research Research Who we are Back to Who we are menu Defining the technology of today and tomorrow. Philosophy We strive to create an environment conducive to many different types of research across many different time scales and levels of risk. Learn more about our Philosophy Learn more Philosophy People Our researchers drive advancements in computer science through both fundamental and applied research.
Skip to main content Login Why Databricks Discover For Executives For Startups Lakehouse Architecture Mosaic Research Customers Customer Stories Partners Cloud Providers Databricks on AWS, Azure, GCP, and SAP Consulting & System Integrators Experts to build, deploy and migrate to Databricks Technology Partners Connect your existing tools to your Lakehouse C&SI Partner Program Build, deploy or migrate to the Lakehouse Data Partners Access the ecosystem of data consumers Partner Solutions
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter Serve Machine Learning Models via REST APIs in Under 10 Minutes Stop leaving your models on your laptop.
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. For large, complex organizations, legacy systems and siloed processes create friction that AI is uniquely positioned to resolve.
Artificial intelligence (AI) has transformed industries, but its large and complex models often require significant computational resources. Traditionally, AI models have relied on cloud-based infrastructure, but this approach often comes with challenges such as latency, privacy concerns, and reliance on a stable internet connection. Enter Edge AI, a revolutionary shift that brings AI computations directly to devices like smartphones, IoT gadgets, and embedded systems.
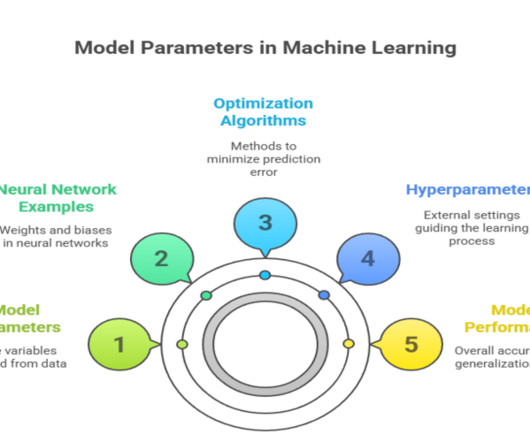
Summary: Model parameters are the internal variables learned from data that define how machine learning models make predictions. Distinct from hyperparameters, they are optimized during training to capture data patterns. Proper initialization and optimization of parameters are crucial for model accuracy, generalization, and efficient learning in AI applications.
Blog Top Posts About Topics AI Career Advice Computer Vision Data Engineering Data Science Language Models Machine Learning MLOps NLP Programming Python SQL Datasets Events Resources Cheat Sheets Recommendations Tech Briefs Advertise Join Newsletter 7 Must-Know Machine Learning Algorithms Explained in 10 Minutes Get up to speed with the 7 most essential machine learning algorithms.
You’ve experienced it. That flash of frustration when ChatGPT, despite its incredible power, responds in a way that feels… off. Maybe it’s overly wordy, excessively apologetic, weirdly cheerful, or stubbornly evasive. While we might jokingly call it an “annoying personality,” it’s not personality at all. It’s a complex mix of training data, safety protocols, and the inherent nature of large language models (LLMs).
Speaker: Chris Townsend, VP of Product Marketing, Wellspring
Over the past decade, companies have embraced innovation with enthusiasm—Chief Innovation Officers have been hired, and in-house incubators, accelerators, and co-creation labs have been launched. CEOs have spoken with passion about “making everyone an innovator” and the need “to disrupt our own business.” But after years of experimentation, senior leaders are asking: Is this still just an experiment, or are we in it for the long haul?
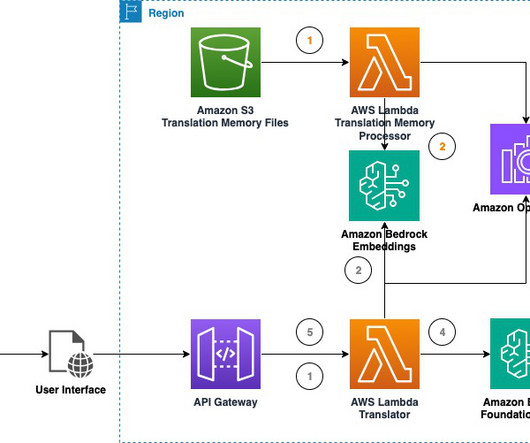
Large language models (LLMs) have demonstrated promising capabilities in machine translation (MT) tasks. Depending on the use case, they are able to compete with neural translation models such as Amazon Translate. LLMs particularly stand out for their natural ability to learn from the context of the input text, which allows them to pick up on cultural cues and produce more natural sounding translations.
This post is divided into five parts; they are: • Preparing the Dataset for Training • Implementing the Seq2Seq Model with LSTM • Training the Seq2Seq Model • Using the Seq2Seq Model • Improving the Seq2Seq Model In
In recent years, data analytics has become a cornerstone of competitive advantage in sports. From Moneyball’s transformative impact on baseball to real-time player tracking in basketball and football, data-driven decision-making is redefining how games are played, coached, and consumed. For data scientists, this presents not only an exciting application area but also a rich source of structured, high-quality datasets perfect for hands-on practice.
Ever waited too long for a model to return predictions? We have all been there. Machine learning models, especially the large, complex ones, can be painfully slow to serve in real time. Users, on the other hand, expect instant feedback. That’s where latency becomes a real problem. Technically speaking, one of the biggest problems is […] The post Accelerate Machine Learning Model Serving With FastAPI and Redis Caching appeared first on Analytics Vidhya.
Many software teams have migrated their testing and production workloads to the cloud, yet development environments often remain tied to outdated local setups, limiting efficiency and growth. This is where Coder comes in. In our 101 Coder webinar, you’ll explore how cloud-based development environments can unlock new levels of productivity. Discover how to transition from local setups to a secure, cloud-powered ecosystem with ease.
Input your email to sign up, or if you already have an account, log in here!
Enter your email address to reset your password. A temporary password will be e‑mailed to you.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.








































Let's personalize your content